
论文:Tuzel O, Taguchi Y, Hershey J R. Global-Local Face Upsampling Network[J]. 2016.
论文算法概述
人脸幻构任务在输入图像分辨率非常小(如10x12像素等)或者在不可控的多姿态多亮度情况下具有很大的挑战性。该论文在07年的Face Hallucination: Theory and Practice中的框架上做改进,提高了精度和效率,利用全局和局部约束使人脸可以高效地被模型化,并且该网络可以进行端到端训练。从理论上,该网络可以分为两个子网络,一个根据全局约束实现了整体人脸的重构,另一个则强化了人脸特定的细节部分并约束了局部图像块的数据分布统计。使用了一个用于超分辨率重构的新损失函数,结合了与训练人脸质量的重构误差作为对抗,使输出有更好的视觉效果。实验证明该方法在数据上和视觉上都达到了最先进水平。
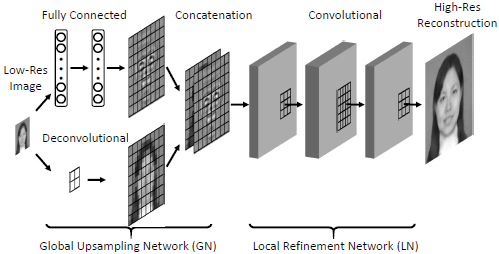
Global Upsampling Network (GN)
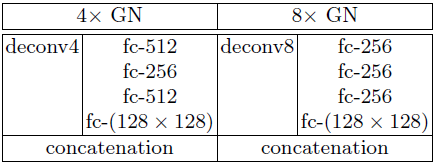
GN网络有两条支路并行处理,在图像上采样的支路中使用反卷积层得到一个大的平滑而缺少细节的图像,使用双线性插值矩阵去初始化反卷积层权重,允许这些权重随着训练而更新,尽管反卷积层权重会更新,但不会更新太多使输出的是正常的平滑上采样图。全局细节生成的支路由全连接层作为编码层的网络实现,在除了最后用于生成128x128的上采样全局细节的层外,每一层的特征图都接ReLU。而且这里编码层无论是上采样4倍还是8倍都采用256维,这主要是因为训练样本有限,全局特征训练容易出现过拟合。最后将上采样的网络支路和全局细节特征生成支路的输出进行拼接,得到2x128x128的张量用于LN。
Local Refinement Network (LN)
LN的结构如图所示,分别对应上采样4倍和8倍任务,分析了三个有不同层数的全卷积网络框架。在每次卷积操作时都对图像做padding保持大小一致,卷积后输入到ReLU。全称没有使用池化,并且滑动步长为1,因此网络学习到了平移不变的非线性,如图2(c),LN通过由GN得到的平滑和细节层,加强了人脸特定的局部特征。此外,重构图的局部数据分布与高分辨率对应图像块的数据分布相吻合(例如平滑的脸颊区域和尖锐的脸部轮廓)。


Training
包含两个阶段的训练过程。第一阶段,通过以最小化重构误差作为条件进行训练,在第二阶段通过最小化重构误差与人脸质量损失函数之间带权重的联合损失来进行网络微调。 重构训练:最小化高分辨率groundtruth和重构图的均方误差,{XL,XH}为训练的低清高清图像对,G(.)是GLN函数。网络的训练采用SGD,mini-batch为5张图像,学习率为10^-8,冲量为0.9.
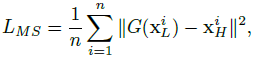
对抗微调:均方误差损失函数更倾向于在有细节部分的区域上的模糊重构,如边缘区域。这里使用一个调整过的损失函数,该损失函数调整用于度量重构质量,而这质量度量是通过鉴别高分辨率和重构图像来实现的,类似于GAN中鉴别器。参考GAN的对抗网络框架与GLN的参数相联合来学习鉴别损失函数。在这里的框架中,鉴别网络D(.)检测由GLN得到的重构图像,它训练过程中,需将输入为重构图像时输出概率最大,输入为真实高分辨率图时输出概率最小,其损失函数如下
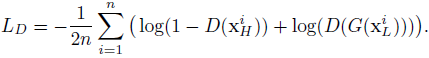
GLN被训练去最小化重构误差LMS,也通过最小化鉴别网络在输入为重构图像时的输出概率来迷惑鉴别器。通过联合均方误差损失和对抗损失来实现,入为权重因子。
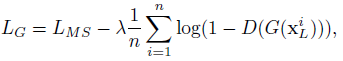
与GAN的训练方式相似,交替地训练,最小化鉴别网络的LD而保持GLN参数固定,再最小化GLN的LG而保持鉴别网络参数固定。作者在每轮交替中对鉴别网络使用10次SGD迭代,对GLN使用50次SGD迭代,共交替1w次。对抗网络由卷积网络实现,共有四层,(1) conv5-16, ReLU, MaxPool 2x2; (2) conv5-16, ReLU, MaxPool 2x2; (3) fc-50, ReLU; (4) fc-2; 使用仅为重构而训练的网络进行对抗网络的微调。对于权重因子入则设置为一个数使初始的对抗损失是均方差损失的1/10。
Experiments
作者做了两个实验,分别在可控条件和非可控条件(in the wild)。可控条件下使用Face Recognition Grand Challenge (FRGC)数据库,这个数据库的是在室内的两种光照条件下的正脸图片,仅有微笑和自然两种脸部表情。作者将里面22149张中的20000张作为训练样本,2149张做测试用,所有图片都要先进行人脸对齐;对于不可控条件下,使用Labeled Faces in the Wild-a (LFW-a)数据库模拟,该数据库是为了训练在非限定条件下的人脸识别而产生的,里面的人脸图像具有各种光照、姿态和表情。共包含来自1680个人的13233个人脸图像,这里使用12000个用于训练,1233个用于测试。对于上采样4倍的任务,人脸大概在20x24像素左右,而8倍的则为10x12左右。低分辨率图像由下采样后使用高斯平滑得到,4倍的设高斯函数的标准差为1.2,8倍的为2.4。



Analysis of the Network Architecture
这里分析网络中的各子模块,(1)训练全局细节生成的网络支路(全连接)GN去直接生成高分辨率图像,这里称为GN-Only;(2)使用仅由双线性插值的上采样图作为输入来训练LN8网络,这里称为LN-Only。如图所示,GN-Only得到了高质量的全局细节,如对称性和典型的脸部特征,而同时平滑了非典型的特征(如脸颊和突出的细节),产生的合成高频部分图像并没有与脸部图像块的分布相一致;而LN-Only的结果是全局细节如典型特征和对称性等没有被保留,而局部图像块的分布统计与脸部图像块的统计相一致,如尖锐的边缘,局部细节也保留也下来。

Adversarial Fine-Tuning
这里比较分析了仅使用重构损失训练GLN和加上对抗误差对GLN进行微调的结果。表明对抗的微调操作提高了生成的高分辨率人脸图像视觉质量,图像更加尖锐,含有更多的典型细节。但这一步对抗微调反而会轻微地减少PSNR分数,如4倍的减少0.01dB,8倍的减少0.25dB。这个结果在当额外的对抗损失没有对人脸的身份进行区别而仅评估生成的图像质量时会出现。论文中分析了均方误差损失和对抗损失之间的权重因子入的影响,发现在入越大即对抗损失占重比越大时,重构人脸图像将会变得更加尖锐而包含给更多的人脸细节,这时我们还需要考虑到这些由人工生成的高频部分对图像的影响。
Color Face Upsampling
人眼对色彩通道(u,v)不敏感,因此对于三通道图像,一种常用的做法是将图像转YUV,对Y分量进行处理,然后使用双线性插值将颜色通道的值填充进去。
Failure Cases
该方法对采用精度不高的对齐方法时没有出现什么大的问题,但对于人脸姿态或表情变化过大时重构精度会下降。