
论文:Kim J, Lee J K, Lee K M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks[J]. Computer Science, 2015.
论文算法概述
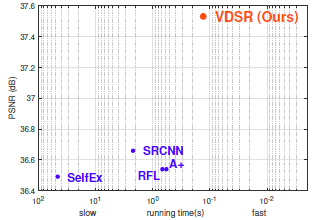
提出一种高精度单图超分辨率重构方法,通过在20层的网络结构中多次级联小滤波器,高效挖掘图像区域中的上下文信息。训练时通过只学习残差的方式以高学习率加快收敛。文中先指出SRCNN的三个缺点:依赖小图像块的上下文信息;训练收敛慢;网络仅能应对一个尺度。
文中算法有以下改进:
1、利用较大图像块的上下文信息。对于单尺度缩放因子,涵盖在小图像块内的上下文信息通常不足以恢复细节,即会有病态矩阵问题(求解方程组时如果对数据进行较小的扰动,则得出的结果具有很大波动,这样的矩阵称为病态矩阵);
2、采用残差学习从而使用较大的学习率加快收敛速度。因为训练图像对具有高度相关,残差则对应于低分辨率和高分辨率图像的差别,所以残差学习会比较有效,这里初始学习率设为SRCNN的10000倍;
3、提出单模型的超分辨率重构方法,以往的方法通常是手动设置缩放因子,而这里发现单模型足以应用与多个缩放因子的重构。
网络结构
整体结构如图所示,先将图像上采样到对应尺寸,使用卷积网络来学习图像细节部分(残差),后将学到的细节部分跟原图叠加得到高分辨率输出,采用残差学习的方式是因为输入和输出高度相关。

训练
采用MSE监督训练。在SRCNN中,在某图像丢弃后网络仍需要保留所有输入细节,同时输出图像完全来自于学习到的特征图。输入输出在经过多个网络层,为端到端的关系则需要长期记忆,所以容易出现梯度暴增或梯度弥散。而这个问题可以通过残差学习来解决,这里损失层输入有三个:残差估计、低分辨率图、高分辨率目标,残差估计与低分辨率图相叠加结果使接近高分辨率目标图。
训练过程中可加大学习率,通过可调节的gradient clipping来防止梯度暴增。gradient clipping的意思是在前向传播与反向传播之后得到的每个权重的梯度diff,这时不像通常那样直接使用这些梯度进行权重更新,而是先求所有权重梯度的平方和sumsq_diff,如果sumsq_diff > clip_gradient,则求缩放因子scale_factor = clip_gradient / sumsq_diff。这个scale_factor在(0,1)之间。如果权重梯度的平方和sumsq_diff越大,那缩放因子将越小,最后将所有权重乘上这个缩放因子后得到的梯度值才用于权重更新,这样可以防止梯度暴增时造成的loss发散(caffe中需要在solver里设置一个超参数clip_gradient)。文中利用gradient clipping把梯度限制在一定范围内[-a/r, a/r],使可以较大的学习率去学习,其中r为当前学习率,a为自己调节的参数。
加深模型能提高性能(论文中实验证明从5到20层,随着层数增加,效果也迅速提升),则更深模型中会有更多的参数。以往的一个模型针对一个缩放因子,这里模型应对于多个尺度,将多个缩放因子产生的图像对集放在一起一同训练,样本生成与SRCNN类似,将图像进行切块,但这里的图像块之间无重叠。对于多缩放因子和单一缩放因子的训练效果如图,发现多缩放因子一起训练效果反而更好。
