论文:Shi W, Caballero J, Huszár F, et al. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network[C]// CVPR. 2016.
Github:https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
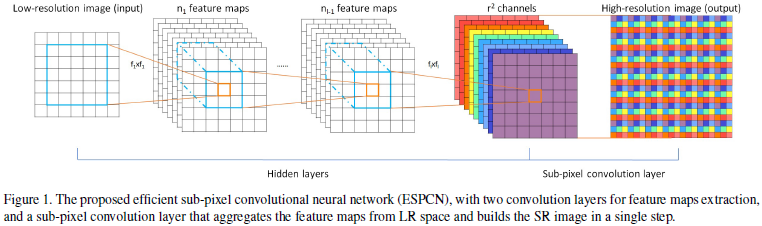
论文算法概述
近期有很多基于深度学习的单图像超分辨率重构方法取得了很好的效果,在这些方法中,在重构之前大都将输入的低分辨率图像上采样到高分辨率的空间中,而这上采样的方法通常是双立方插值。这就意味着超分辨的操作是在高分辨率的空间中进行的。论文中证明了这种做法是局部最优的,并且计算复杂。论文中上采样由最后一层实现,网络直接对低分辨率图像进行特征提取,图像小计算量也小,在单K2 GPU上对1080的视频做处理能达到实时的效果。
网络中l = 3, (f1; n1) = (5; 64),(f2; n2) = (3; 32),f3 = 3。在训练阶段,输入的高清图像被切分成17r x 17r像素块,r为上采样因子,同时低分辨率输入由高分辨率图像通过高斯模糊和r的下采样得到17x17。使用tanh替换relu作为每层的激活函数。而所谓的亚像素卷积层为滑动步长是1/r的卷积层来实现上采样。