代码:http://mmlab.ie.cuhk.edu.hk/projects/FSRCNN.html
论文:Chao Dong, Chen Change Loy, Xiaoou Tang. Accelerating the Super-Resolution Convolutional Neural Network, in Proceedings of European Conference on Computer Vision (ECCV), 2016
论文算法概述
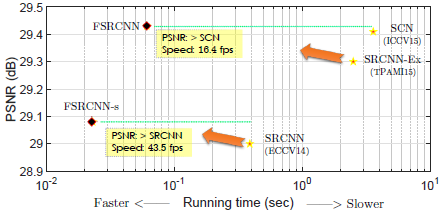
提出了对SRCNN的加速版本,主要改动有三方面:1、在网络的最后一层引入了反卷积层,并且网络直接由原始的低分辨率图像到高分辨进行学习而不需要先对原图进行插值。2、通过在映射前降低输入特征的维度而后再扩展回去来重新设定网络层; 3、采用更小的滤波器和更多的网络层。该模型比旧版的快40倍,并且重构质量更好,在CPU中运行能达到实时。
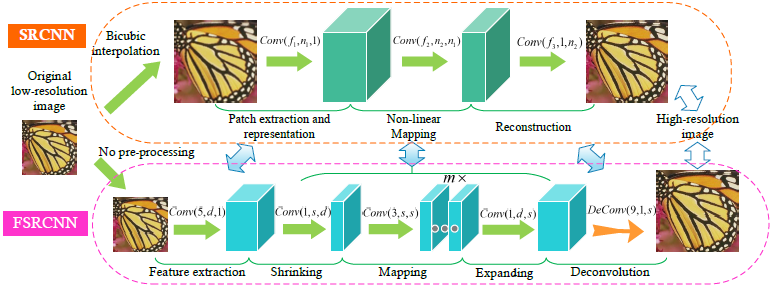
FSRCNN可被分为5部分
Feature extraction,Shrinking,Non-linear mapping,Expanding,Deconvolution。前面4部分为卷积层,最后一部分为反卷积。
-
Feature extraction: 这部分与SRCNN的类似,但输入图像不一样。FSRCNN以原始的低分辨率图像作为输入(SRCNN需将原图插值放大再输入)。在SRCNN中第一层网络滤波器大小设为9,因为输入图像是由原图升采样后得到的,所以原图5 x 5的图像块可以几乎涵盖升采样后的9 x 9图像块的信息。所以这里以原图输入采用5 x 5的卷积核。而通道数与SRCNN一样设为1,滤波器数量n可以看成是低分辨率特征的维度d。
-
Shrinking: 在SRCNN中映射部分紧接在特征提取后面,然后高维度的低分辨率特征直接映射到高分辨率特征空间。然后这种低分辨率特征的维度很大,在映射过程中计算量大,这种情况在其他深度学习任务中也常会遇到,如可采用1 x 1的卷积层来减少运算量。出于相同的考虑,这里在特征提取后面添加了卷积核大小为1的收缩层来减少低分辨率特征维度,卷积核数量s要小于前面低分辨率特征维度d,表示为Conv(1; s; d)。
-
Non-linear mapping:非线性映射是影响这超分辨率重构效果中最重要的一步。对于效果和网络规模的交换,采用不大不小的3 x 3卷积核。为了获得与SRCNN一样好的效果,采用了多个3 x 3的网络层来代替1个。映射层数m决定了映射的准确率和复杂度,为保持一致,所有映射层采用卷积核为相同的数量s,则非线性映射部分表示为m x Conv(3; s; s)。
-
Expanding:膨胀层起到的作用与收缩层相反。收缩操作减少了低分辨率特征的维度提高计算效率。然而,如果从这些低维特征来直接生成高分辨率图像,这样效果会很差。因此在映射部分后添加了膨胀层来扩展高分辨率特征维度,为保持与收缩层的一致性,也采用1 x 1卷积核,数量与用在低分辨率特征提取上的一样。与收缩层Conv(1; s; d)相反,膨胀层是Conv(1; d; s)。实验证明如果没有这个膨胀层,效果会差些。
-
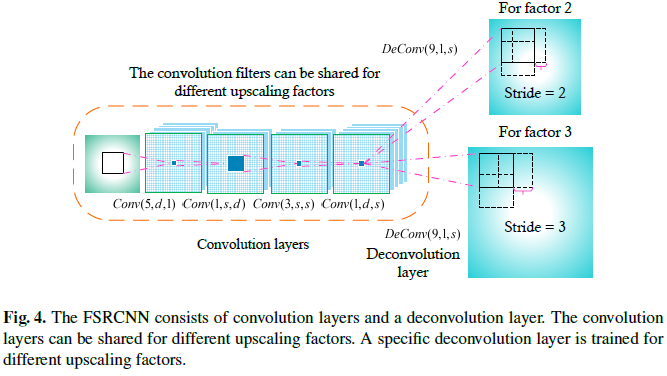
Deconvolution:最后一部分是反卷积部分,由一系列的反卷积滤波器来实现上采样以及聚集前面特征。反卷积可以被看成是卷积的逆操作。对于卷积,若卷积步长为k则输出是输入的1/K倍。相反地,如果调换了输入和输出的位置,则输出是出入的k倍,如图4所示,设步长k=n,即为上采样因子,得到的输出直接用于重构高分辨率图像。
-
PReLU:对于每个卷积层后面的激活函数,建议使用 Parametric Rectified Linear Unit (PReLU) 来代替普通的ReLU,目的主要是为了避免由ReLU上零梯度造成的无效特征。
-
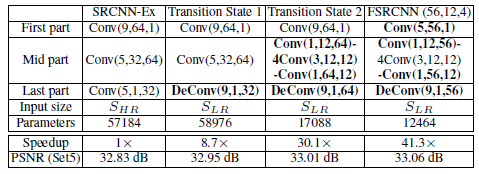
Overall structure:Conv(5; d; 1)——PReLU——Conv(1; s; d)——PReLU ——m x Conv(3; s; s)——PReLU ——Conv(1; d; s)——PReLU——DeConv(9; 1; d),有三个影响较大的变量:低分辨率特征维度d,缩减层滤波器数量s,映射层深度m,则其运算复杂度为:O{(25d + sd + 9ms^2 + ds + 81d) SLR} = O{(9ms^2 + 2sd + 106d) SLR};
-
Cost function:损失函数采用均方误差MSE:
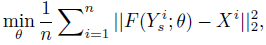 Y和X分别是训练集中低分辨率和高分辨率图像块,而F是网络对于Y在对应参数下的输出,全部参数的整个优化流程使用SGD进行普通的反向传播。
Y和X分别是训练集中低分辨率和高分辨率图像块,而F是网络对于Y在对应参数下的输出,全部参数的整个优化流程使用SGD进行普通的反向传播。
SR for Different Upscaling Factors
所有卷积层都表现为低分辨率图像的特征提取算子,而仅有最后面的反卷积层包含了上采样因子的信息,所以卷积滤波器对于不同的上采样因子都几乎一样。基于这点,可以通过迁移卷积滤波器来达到快速训练和测试。在实践中,预先基于一个上采样因子来训练好一个模型,然后在训练时,应对其他的上采样因子仅微调反卷积层,而卷积层不变。微调很快且性能不差。在测试时,只运行卷积过程一次,然后根据对应的反卷积层来上采样到对应大小。
Training samples
为准备训练样本,先对原始的训练样本通过合适的降采样因子来降采样获得低分辨率图像。然后将该低分辨率图像以步长k裁剪成一系列f x f的图像块,对应的高分辨率图像(大小为(n x f)^2),也由实际图像裁剪而来,这些高分辨率和低分辨率的图像对作为原始的训练样本。对于padding,实验发现对输入或输出特征图做padding影响不大,则文中在所有层中都没加padding,所以对于不同的网络设计没有需要改变子图像块的大小。另外一个影响子图像块大小的因素是反卷积层。在使用caffe进行训练时,反卷积滤波器输出大小为(n x f - n + 1)^2而不是(n x f)^2,所以在高分辨率子图像块上需要裁剪n-1个像素的边界。最后对于x2,x3,x4,将低分辨率/高分辨率子图像块大小分别设置为10^2/19^2, 7^2/19^2和6^2=21^2。