主页:http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
论文:Dong C, Chen C L, He K, et al. Learning a Deep Convolutional Network for Image Super-Resolution[M]// Computer Vision – ECCV 2014. Springer International Publishing, 2014:184-199.
论文算法概述
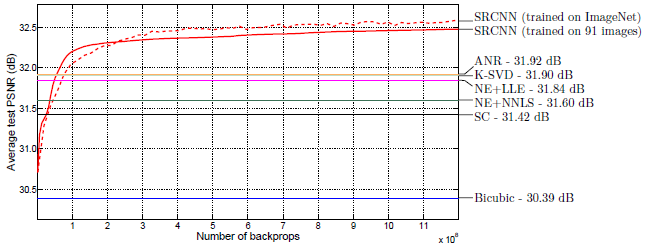
提出的基于深度卷积网络用于单图像的超分辨率重构,直接学习低分辨率和高分辨率图像之间的映射关系,联合优化所有网络层进行端到端训练。并建立了传统的基于稀疏编码的SR方法与基于深度学习的SR方法的联系,由此提供SR网络设计的方向。
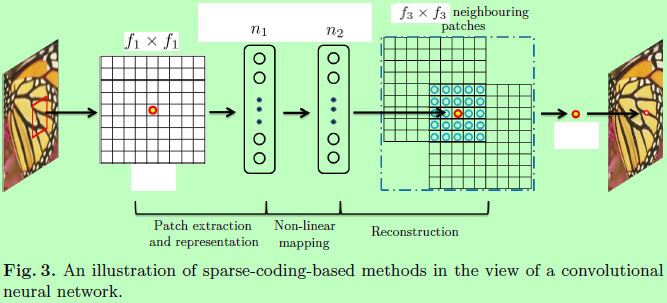
整个流程包括三个步骤:1、图像块提取与表示;2、非线性映射;3、重构;测试时先使用双立方插值将低分辨率图像放大到目标大小,将放大后的图像进行映射和重构得到高分辨率图像。训练时使用清晰图像,按一定步长将输入图像先缩小后放大得到相对模糊的图像,以一定大小和步长有重叠地截取模糊的图像块和原图图像块作为样本对(输入图像和标签),进行训练,因为图像块的截取有重叠,则映射得到的高分辨率图像块也有重叠,而传统方法中是以取平均的方式得到结果,这种取平均的方式可以认为是一种在一组特征图上的预定义滤波器,所以这里提出使用一个卷积层。最后使用重构图和标签图的均方误差MSE作为损失函数进行训练。
实现细节
文中用于实验的网络设置参数为f1=9,f3=5,n1=64,n2=32。并会根据每个上采样因子{x2,x3,x3}来针对性训练网络。在训练阶段输入图像为32 x 32的图像块,把每个图像块当作是一张单独的图像。先将原图按对应的缩放因子进行下采样,然后使用双立方插值上采样的原来大小。使用一定的步长有重叠地裁切图像,则这91图像使用步长为14时将会大约得到24800张子图像,作者尝试过采用更小的步长,但没有明显的性能提升。且据作者观察,这些训练样本对于该网络已经足够了。
训练中为避免边界影响,所有卷积层都没有padding,并且网络输出更小的尺寸(20 x 20),而损失函数仅针对原图中心20 x 20的图像块与网络输出进行计算。在测试的时候,该网络可应用于任意大小的图像,并会给出足够的zero-padding来使输入输出大小一致。为解决边界影响,在每个卷积层中,在relu之前的输出都根据输入有效数据的数量来进行归一化,这些可以预先计算好。卷积核的权重由0均值0偏置0.001标准差的高斯分布生成,前两层的学习率为0.0001,最后一层为0.00001。