
论文: Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition[J]. 2018.
Github: https://github.com/deepinsight/insightface
论文算法概述
为了提高softmax loss的辨别能力,提出一种新的监督信号additive angular margin(ArcFace,cos(theta + m)),基于角度空间在L2归一化的权重和特征的上,直接最大化决策边界。
Introduction
基于深度学习的各种人脸识别方法,其不同点主要在三个方面。
-
训练数据:目前有很多公开的人脸识别数据库可用于训练,如VGG-Face、VGG2-Face、CAISAWebFace、UMDFaces、MS-Celeb-1M和MegalFace等,身份数量从几千到50万不等。尽管MS-Celeb-1M和MegaFace的身份数量较大,但也有标注噪声和长尾分布的问题。相比之下,Google的私有训练库甚至有几百万身份的数据从Face Recognition Vendor Test (FRVT)最新的性能报告可以看到,依图基于自己私有的1.8亿的人脸训练样本训练的模型达到了榜首。训练样本数量很重要,也因为训练样本的不同,导致很多人脸识别论文结果难以复现。
-
网络结构和设置:能力较强的卷积网络,如ResNet和Inception-ResNet可以取得比VGG和Google Inception V1网络要好的性能。对于不同的应用,要权衡好速度和精度。
-
loss函数的设计:
-
Euclidean margin based loss。很多论文中使用softmax分类层在一系列已知身份样本中训练,然后提取网络的中间层作为特征向量,用于推广识别训练身份以外的人。后提出的Center loss、Range loss和Marginal loss作为额外的惩罚项去压缩类内差距或加大类间差距去提高识别率,但这些都还仍然需要结合softmax去训练模型的。然而基于分类的方法会有一个问题,就是在分类层的GPU显存消耗问题,分类层把每个身份当成一个类别进行训练。当身份数达到百万级时,显存会很紧缺,同时还会有每个身份的数据均衡和缺少的问题。contrastive loss和Triplet loss使用成对的训练策略。contrastive loss函数包含有正对和负对。该loss的梯度将正对拉到一起,将负对推开。Triplet loss最小化anchor和正样本的距离,最大化anchor和负样本的距离。然而contrastive loss和Triplet loss的训练过程中对训练样本对的选择很关键,选择过程的技巧性很大。
-
Angular and cosine margin based loss。Liu等提出了一个large margin Softmax (L-Softmax),通过给每个身份添加乘法角(multiplicative angular)约束去提高特征的区分度。SphereFace cos(m x theta)将L-Softmax应用到人脸识别上,并进行权重规范化。由于cos函数的非单调性,所以在SphereFace中使用了一个分段函数去保证这个单调性。在训练SphereFace时,Softmax loss会结合来辅助使用,以确保收敛。为了克服SphereFace的优化难度,有人提出additive cosine margin cos(theta)-m,将angular margin移到cosine空间。这样实现和优化都会比SphereFace简单。Additive cosine margin比较容易复现并在MegaFace中达到最优(TencentAILab FaceCNN v1)。相比于基于Euclidean margin的loss函数,基于angular和cosine margin的loss函数更明确地在这超球面空间上添加区分约束,这样本质地匹配到人脸在这个空间的先验。
我们知道,上面提到的三个方面,从数据、网络到loss,分别对人脸识别模型性能的影响从高到低。而这篇论文,作者也主要从这三个方面去提升性能。
-
-
Data。将最大的公开数据库MS-Celeb-1M进行自动和人工提炼。发现MegaFace的一百万干扰图和FaceScrib数据集有上百张重复,这里也手动剔除了。
-
Network。使用VGG2作为训练样本,并关于网络设置进行大量实验并在LFW、CFP和AgeDB上进行测试。
-
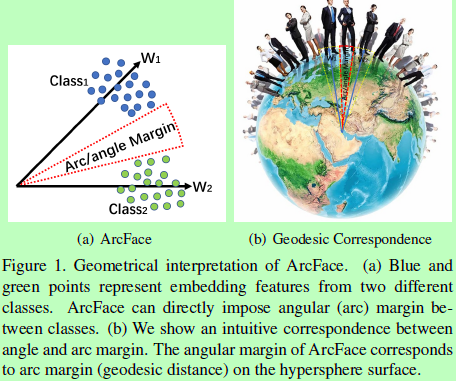
Loss。提出一个新的loss函数,additive angular margin (ArcFace),去学习高区分度的人脸特征。如图1所示,提出的loss函数cos(theta+m)基于L2规范化的权重和特征在角度空间上直接最大化决策边界。
From Softmax to ArcFace
2.1. Softmax
Softmax loss最广泛使用的分类损失函数,公式如下:

其中xi表示深度特征的第i个样本,属于类别yi。特征维度d,在多篇论文中一般维度都设成512。Wj表示最后一层全连接层的权重W的第j列,b是偏置项。Batch size和类别数分别是m和n。传统的softmax loss常被用于人脸识别任务,但是softmax loss并没有明确地使正对的相似度更高和负对的相似度更低,这样就导致了其性能的不足。
2.2. Weights Normalisation

2.3. Multiplicative Angular Margin

2.4. Feature Normalisation
特征归一化被广泛用于人脸验证等,从基于L2归一化的欧式距离和cos距离来看,L2范数对使用softmax loss训练的人脸特征来说是有益的。提取自高质量正脸的特征具有较高的L2范数,而模糊姿态大的L2范数则较小。Ranjan等人将L2约束添加到特征描述器里,限制特征落在一个固定范围的高球面空间上。在已有的深度学习框架中对特征进行L2归一化很容易实现,并能明显提高人脸验证的性能。Wang等人指出,当提取自低质量人脸图像的特征范数很小时,其梯度范数可能会非常大,这样很容易会导致梯度暴增。
我们可以从前面提到的内容看到,对于在超球面的度量学习来说,对特征和权重进行L2归一化是一个很重要的步骤。在特征和权重归一化的做法之后的新方法是,去除径向变化,把每个特征都分布到一个超球面上。
| 跟随多篇论文的做法,我们将基于L2归一化的 | xi | 固定,并将其缩放到s,其中s是超球面的半径,这里实验中设为64。基于特征和权重归一化,我们可以得到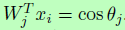 |
如果特征归一化应用到SphereFace,那么我们可以得到特征归一化后的SphereFace,定义为SphereFace-FNorm:
2.5. Additive Cosine Margin
在一些论文中,angular margin m被移出到cos theta外面,因此他们提出了cosine margin loss函数: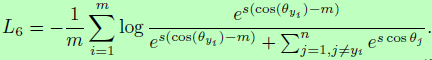
在这篇论文中,我们将cosine margin m设置为0.35,与SphereFace相比,additive cosine margin(Cosine-Face)有三个优势:1)很容易实现且没有微妙棘手的超参数;2)更清晰,且在没有Sofemax监督下可以收敛;3)性能提升明显。
2.6. Additive Angular Margin
尽管cosine空间和angular空间可以一对一映射,但两个margins还是有区别的。事实上,angular margin相对于cosine margin来说具有更清晰的几何解释。angular空间的margin对应这超球面上的arc距离。
我们在cos theta内添加一个angular margin m。因为cos(theta + m)在theta属于[0,pi-m]时,是比cos theta小的,对于分类任务,这约束更严格。我们定义提出的ArcFace为:
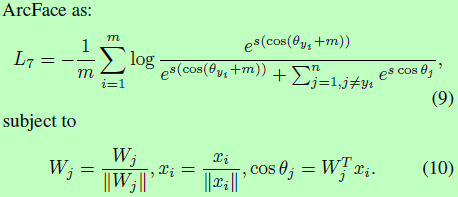
如果我们将提出的additive angular margin cos(theta + m)进行展开,得到cos(theta+m) = cos(theta)cos(m)-sin(theta)sin(m)。与additive cosine margin cos(theta)-m相比,ArcFace很相似,但margin由于sin(theta)的关系,是动态的。
在Figure 2,我们解释了提出的ArcFace,angular margin对应arc margin。相比于SphereFace和CosineFace,我们提出的ArcFace更容易用几何解释。
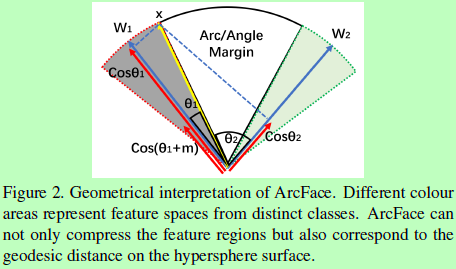
2.7. Comparison under Binary Case
为了更好理解从Softmax到提出的ArcFace的过程,我们给出了基于二分类的决策边界。基于权重和特征归一化,这些方法的主要区别在于我们放出的margin。

2.8. Target Logit Analysis
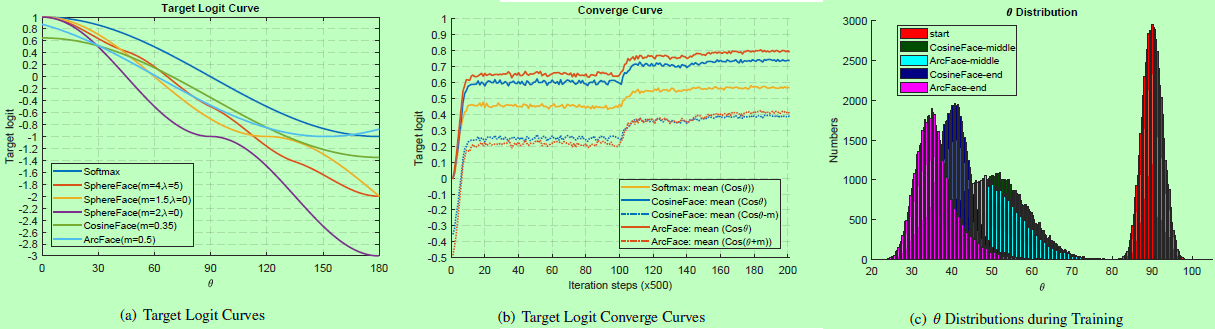
为了研究为什么SphereFace、CosineFace和ArcFace能提高人脸识别性能,我们分析了训练过程中的目标对数曲线和theta分布。这里我们使用LResNet34E-IR网路和精炼过的MS1M数据库。如图4(a)为Softmax、SphereFace、CosineFace和ArcFace的目标对数曲线。对于SphereFace,最好的设定是m=4,入=5,这样的曲线与m=1.5和入=0相似。但SphereFace的实现需要m为一个整数。当我们尝试最小化multiplicative margin,设m=2和入=0时,训练无法收敛。因此,从softmax轻微减少目标对数曲线会在增大训练难度并提高性能,但减少太多会导致训练发散。
CosineFace和ArcFace都这样。如图4(a)所示,CosineFace将目标对数曲线往y轴负方向移动,而ArcFace则移向x轴负方向。现在我们可以很容易明白从Softmax到CosineFace和ArcFace的性能提升的原因了。对于ArcFace,margin m=0.5,目标对数曲线在theta属于0到180度时,非单调递减。事实上,这目标对数曲线在theta大于151.35度时上升。然而如图4(c),theta在90度时为高斯分布,从随机初始化的网络开始,最大的角度是105度。而在训练时,这ArcFace的上升间距几乎从未达到。因此,我们并不需要明确地处理这个问题。
在图4(c),我们展示了CosineFace和ArcFace在训练的三个阶段(开始、中间、结尾)的theta分布。这分布的中心逐渐从90度到35-40度。在图4(a),我们可以看到ArcFace的目标对数曲线在30-90度之间时比CosineFace的低。因此,在这个阶段上,提出的ArcFace比CosineFace的margin惩罚更严格。在图4(b)中展示了Softmax、CosineFace和ArcFace在训练时的目标对数曲线。我们也可以发现ArcFace的边界惩罚在开始时会比CosineFace强,如图中红点线比蓝点线要低。在训练的末尾,ArcFace收敛得比CosineFace要好,如图4(c)中theta的直方图在更左边,而且图4(b)中的目标对数曲线更高。从图4(c)中可以看到,几乎所有的theta s在训练的末尾都比都小于60度。超过这个区域的样本都属于难例,跟噪声样本一样。尽管CosineFace的边界惩罚在theta小于30度时更严格(如图4a),但这个区域甚至到训练的末尾都很少会触及到(如图4c)。因此,我们知道为什么SphereFace在相对较小的margin下,还能够获得很好的性能。
总之,在theta属于60到90度之间时,添加太多的margin惩罚可能会导致训练发散,如SphereFace(m=2,入=0)等。当theta属于30到60度时,添加margin可能会提升性能,因为这部分对应着最有效的难度适当的负样本。在theta小于30度时,加大margin无法明显地提升性能,因为这部分对应着最容易的样本。当我们回到图4(a),并将曲线在30到60度范围内进行排序,我们就可以知道为什么从Softmax、SphereFace、CosineFace到ArcFace的性能会得到提高了。需要注意的是,这里30和60度都是为了容易和困难训练样本而评估设置的较为粗糙的阈值。
Experiments
Training data:使用VGG2和MS-Celeb-1M。其中VGG2直接使用而不进行精炼,其训练集有8,631个身份共310w图像,测试集有500个身份17w图像。MS-Celeb-1M包含10w身份1000w图像,为了减少噪声样本,我们将每个身份的所有人脸图像通过计算与身份中心图片的距离进行排序。对于一个特定身份其人脸图像的特征向量与特征向量中心距离较大的自动剔除。然后进一步手动复查剔除阈值附近的样本。最后得到的数据集包含8.5w身份的380w图片。
Validation data:使用LFW、CFP和AgeDB作为验证集。
Test data:使用自动和手动去噪后的MegaFace。

