论文: Wang F, Jiang M, Qian C, et al. Residual Attention Network for Image Classification[J]. 2017:6450-6458.
论文算法概述
提出了一种使用注意机制(attention mechanism)的卷积神经网络,主要有以下内容。
-
Stacked network structure:Residual Attention网络由多个Attention Modules组成,这被堆叠的结构是混合注意机制的基本应用,不同类型的attention可以在不同的attention modules中被提取。
-
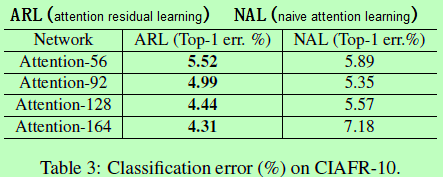
Attention Residual Learning:直接堆叠Attention Modules可能会导致性能下降,因此作者提出了一种attention residual learning机制去优化多达百层的Residual Attention Network。
-
Bottom-up top-down feedforward attention:Bottom-up top-down feedforward结构,即为先降采样后上采样的呈沙漏状的结构。文中将这种结构作为Attention模块的一部分,去为特征添加soft weight。

Residual Attention Network
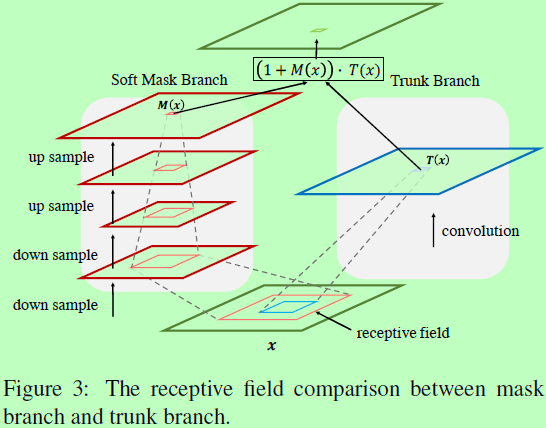
这里的Residual Attention Network是由多个attention模块构成,每个模块分成两个分支:mask分支和主干。主干用于特征处理,这部分可以改成其他任何优秀的网络结构。作者采用pre-activation Residual Unit、ResNeXt和Inception作为这里Residual Attention Networks的基本单元去构建Attention模块。设主干输入x输出T(x),而mask分支使用bottom-up top-down结构(先下采样后上采样的形式)来学习相同大小的mask M(x),去控制主干的输出,则Attention模块的输出为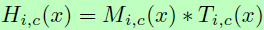 ,其中i为空间位置,c为通道下标。
,其中i为空间位置,c为通道下标。
在Attention模块中,attention mask不仅可以在前向传播时充当特征选择器,还能在反向传播时去过滤无用的梯度更新,提高训练效率。每个主干分支都有其对应的mask分支去学习该部分特征特定的attention,如上图1的热气球所示,来自低层网络的蓝色特征对应着天空的mask去消除背景,而对来自顶层的部件特征则对应着气球目标的mask。随着层的增加,attention mask会越来越精确。
Attention Residual Learning
但直接堆叠Attention模块会导致性能下降,首先,与mask的从0到1的反复点积会使特征逐渐退化,层数深了退化会很明显。再者,soft mask可能会破坏主干的属性,如残差单元中的identical mapping。
为了解决上面问题,作者提出了attention的残差学习,假设soft mask单元可以构成 identical mapping,那么其性能应不比没有attention时差,因此可将Attention模块的输出改成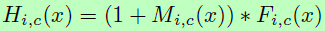 ,M(x)的范围在[0,1],当M(x)逼近0时,H(x)将逼近原始特征F(x)。这里的堆叠的attention残差学习与原始ResNet中的残差学习有点不一样,原始的是
,M(x)的范围在[0,1],当M(x)逼近0时,H(x)将逼近原始特征F(x)。这里的堆叠的attention残差学习与原始ResNet中的残差学习有点不一样,原始的是 ,F(x)为残差函数。而在这里F(x)则表示为通过网络得到的原始特征。实验中作者通过这种方法可将网络加至452层。
,F(x)为残差函数。而在这里F(x)则表示为通过网络得到的原始特征。实验中作者通过这种方法可将网络加至452层。
Soft Mask Branch
这里mask分支包含快速的前向步骤和自顶而下的反馈步骤。前一个操作可以快速提取整张图的全局信息,而后者则使原始特征图整合全局信息。在卷积神经网络中,这两步被呈现在bottom-up top-down的全卷积网络中。对于输入,在少量残差单元后采用了多次的max pooling去快速增加感受野。在得到最小分辨率后,通过一个对称的topdown结构去扩展全局信息来引导每个位置的输入特征。又在一些残差单元后,使用线性插值上采样输出,使输出与原来降采样前的输入特征图大小一致。在经过两个连续的1x1卷积层后,使用一个sigmoid层去归一化输出到[0,1]。同时,作者也使用bottom-up和top-down两部分间添加skip connections去提取不同尺度的信息,如图2所示。

Spatial Attention and Channel Attention
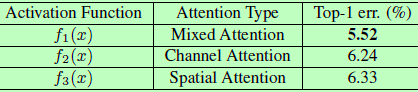
这里attention由mask分支提供,会受主干分支的特征影响而改变。但也可以通过修改soft mask输出之前的激活函数中的归一化步骤来对attention进行约束。作者使用了三种类型的激活函数,分别对应mixed attention、 channel attention和spatial attention。Mixed attention f1没有添加约束,对每个通道和空间位置使用简单的sigmoid;Channel attention f2则在每个空间位置的所有通道上使用L2归一化,而去掉了空间信息;Spatial attention f3在每个通道的特征图内进行归一化,并用sigmoid去得到与仅空间信息相关的soft mask。作者实验中发现mixed attention,即使attention随特征自适应改变而不加额外约束的效果最好,公式如下: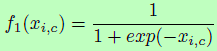
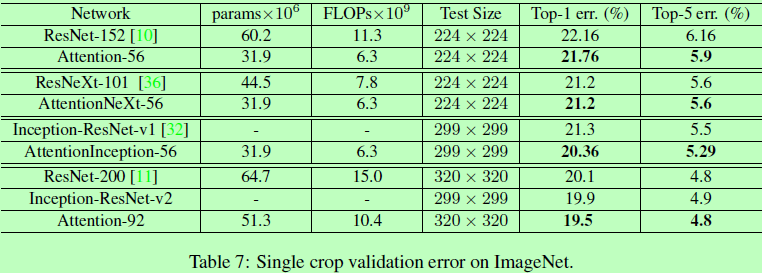
Experiments