
论文: Chen Y, Li J, Xiao H, et al. Dual Path Networks[J]. 2017.
Github: https://github.com/cypw/DPNs
论文算法概述
ResNet使特征可共享与重复利用而DenseNet有助于新特征的挖掘,这里论文提出的DPN结构则进行了融合,使同时具有ResNet和DenseNet的这两个优点,并且在计算量和内存方面都更有优势。在ImageNet 1k分类中,小的DPN网络比ResNeXt-101(64 x 4d)准确率高,并且模型小26%,计算量少25%,内存消耗少8%;而更深一点DPN-131比最好的单模型效果好并且快3倍。
Dual Path Architecture
结构定义如下:
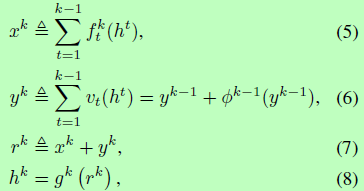
其中公式5引用densely connected path的使能发掘新特征;公式6引用自residual path使普通特征能够共享并重复利用;公式7定义了dual path,集成它们并送入公式8中的最终的变换函数里。这最终的变换函数gk(.)生成当前状态,用于下一次映射或预测。
Dual Path Networks
如图a为ResNet的网络结构,左边矩形内从上往下输入,途中另多起一条分支输入到1x1、3x3、1x1卷积中,然后该分支的输出与主干的x相加得到结果,为一个模块;图b中为DenseNet的网络结构,同样左边从上往下输入,途中另起一分支,该分支输出与主干的x拼接,使通道数增多。
而下图2(d)(e)中显示的是实验中使用的dual path architecture的例子。图d和e表示着同一个意思,每个micro-block都带一个bottleneck(1 x 1 - 3 x 3 - 1 x 1卷积),随后的1 x 1卷积的输出分成两个部分,一部分是如ResNet中的按像素相加,另一部分是如DenseNet中的concat拼接。注意输入x是两条分支,看图d。为了提高每个micro-block的学习能力,参考ResNeXt在第二层采用组卷积。考虑到ResNet比比DenseNet应用更广泛,所以在实践中选择以ResNet作为支柱,再添加一些densely connected path去组件DPN。这样的设计也有助于减缓DenseNet中的宽度增加和显存消耗。
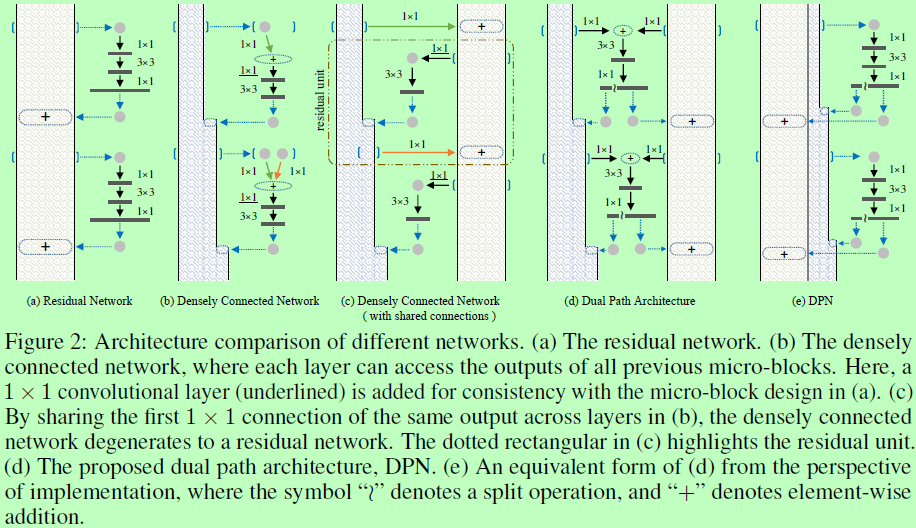
表1展示的是具体的结构设置,G表示group的数量,k对应densely connected path中channels的增加。

Experiments


