论文: Larsson G, Maire M, Shakhnarovich G. FractalNet: Ultra-Deep Neural Networks without Residuals[J]. 2016.
Github: https://github.com/gustavla/fractalnet https://github.com/snf/keras-fractalnet
博客: http://blog.sina.com.cn/s/blog_7147954d0102wbvx.html
论文算法概述
-
引入FractalNet,一种基于自相似性(selfsimilarity)的神经网络架构的设计策略。这种设计出来的网络包含有不同长度的相互交错的子路径,而不包含任何pass-through connections:每个内部信号在进入随后的层以前都会先进行滤波和非线性变换。
-
该设计可以使网络达到很深的程度,可作为与resnet相对的构建极深的网络的另外一种方式。FractalNet表明对于训练极深的神经网络路径长度(path length)是关键,而残差仅是附带的,而关键在于FractalNet和ResNet的共同特点,那就是网络深,但在训练时梯度传播的路径短而高效。
-
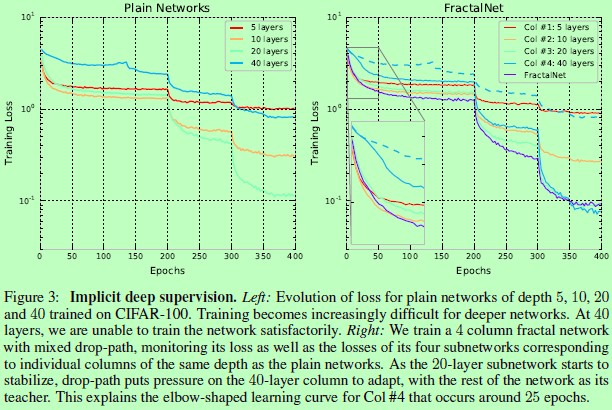
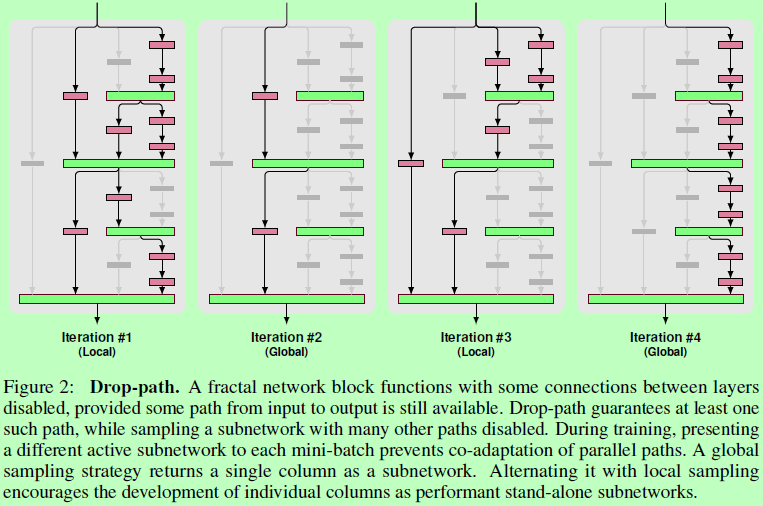
提出了drop-path,对于极深的fractal网络的有着直观和有效的正则化作用,而且drop-path也可以看成是一种对fractal网络中耗时和精度之间进行折衷的方法。
Fractal Networks

如图1中左边是fractal架构简单的拓展方式,由原本的形态分裂成两条分支,最后以逐元素相加取平均(element-wise mean)的方式进行联合。设f1为输入输出之间的单一层,则可将结构由 ,递归拓展成
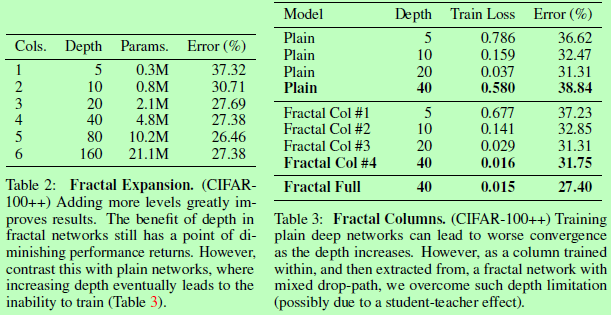
,递归拓展成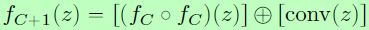 。网络深度可以定位为是输入到输出之间的最长路径上的卷积层数量,则如右边一个block为f4,其中最常路径上卷积层数量为8,即深度为8。实际应用中,图1中的卷积操作也可以更换成其他操作,联合的方式也可以换成其他的。
。网络深度可以定位为是输入到输出之间的最长路径上的卷积层数量,则如右边一个block为f4,其中最常路径上卷积层数量为8,即深度为8。实际应用中,图1中的卷积操作也可以更换成其他操作,联合的方式也可以换成其他的。
Regularization via Drop-path
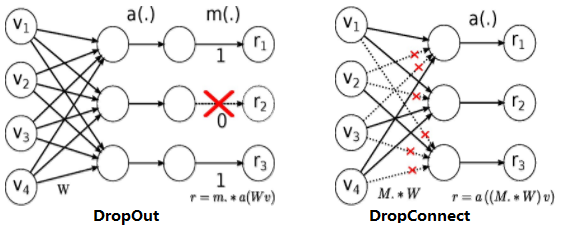
Drop-path,其用意与DropOut和DropConnect相似,dropout是为了防止激活输出之间的相互适应,而drop-path则是通过随机联合层的操作来防止并行分支之间的相互适应,达到正则化效果。即若不这样做,容易变成以网络的一个输入分支为向量,另外的分支为修正偏置项,各分支之间具有较强的耦合性,容易出现过拟合。作者主要考虑了两个采样策略:
-
Local:在一个联合(join)中,以一定概率随机屏蔽一些输入,并确保至少保留一个输入。
-
Global:在整个网络中,选取一条单一的路径。促使网络中每条通道都是一个独立的强预测器。
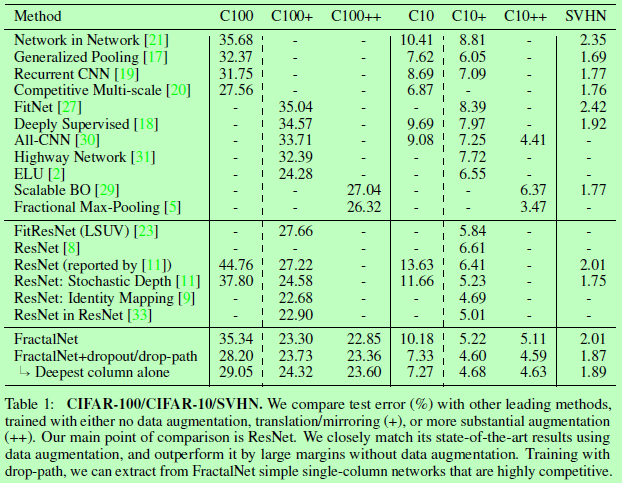
在论文实验中,作者采用50%的Local和50%的Global采样。而实验结果还显示,数据扩增对如ResNet等网络作用很大,而在使用Drop-path进行正则化后,可以使网络在没有数据扩增的情况下也能达到郊有竞争力的效果。
Experiments