
论文: Sun Y, Wang X, Tang X. Sparsifying Neural Network Connections for Face Recognition[J]. Computer Science, 2015:4856-4864.
论文算法概述
该论文提出了一个基于神经元相关的权重选择标准,并用实验验证了从每次迭代训练得到的模型中选取有用神经元连接的效率。在一个合适的稀疏结构下,这里提出的sparse ConvNet能够明显地提高DeepID2+模型的准确率,在LFW中从98.95%到99.30%(相同训练集)并且参数数量是原来的12%。而权重选择中,重点是保留强相关摘除弱相关的神经元之间的连接,其中两个相连接神经元的相关性由它们激活情况的相关程度决定。
基本流程是先训练好一个基本的卷积网络,然后从高到底逐层进行选择性地裁剪,每个只稀疏一层,然后重新训练(以旧模型微调)该整个网络。前面迭代得到的模型用来计算神经元的相关性,并用来初始化随后的稀疏模型。但而如果直接训练一个稀疏模型很难得到好的效果,因为这稀疏模型在没有密集模型的帮助下很容易陷入局部最优。越密集的模型就有越多的参数,自由程度就越高,就越容易去避免陷入局部最优,因此更密集的模型可以为稀疏模型提供较好的初始化参数。
Baseline model
基础模型设置如下图所示,其中后面两个局部连接层的目的是在不同的人脸区域中学习不同的特征,并增加模型拟合的能力。后面接着一个512维的全连接层,作为最终的特征表达层。与DeepID2+相似,以识别和验证两个监督信号添加到最后一层和前面几个层中进行监督训练。
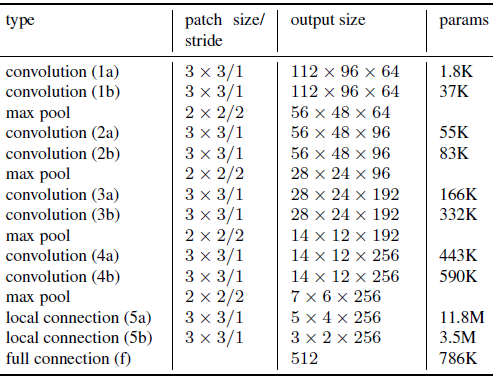
Sparse ConvNets
以训练好的baseline模型N0为基础,从后往前逐层删除连接。当层Lm被稀疏后,得到的新模型Nm是以前一次稀疏的模型Nm-1作为初始值进行训练的。这个过程在caffe等框架中,可以用一个只有0和1的与网络层权重参数大小一致的二值化矩阵(dropping matrix)来实现,如在每层前向传播之前,其权重参数先与dropping matrix进行点积,而反向传播时做法也一致。
稀疏的原则是保留强相关而去除弱相关的神经元之间的连接。注意强负相关的神经元也很重要,有助于减少虚警。而在实践中发现适当保留少部分的弱相关神经元对模型性能也有促进作用。
首先考虑的是权重不共享的全连接和局部连接层,权重和连接都是一对一的。在给定当前层的神经元ai,ai与前面层连接的k个神经元bi1,bi2…bik。则ai与每个bi的相关系数计算如下:
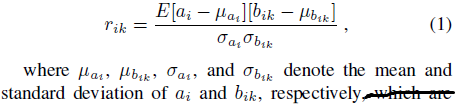
正相关和负相关同样重要,先将所有正的r_ik进行降序排序并分为两份,随机取前半部分的lambdaSK+个系数和后半部分的(1-lambda)SK+个。其中S自行设定的稀疏程度(范围在0到1之间),K+表示正的相关系数的个数,lambda在作者的实验中设为0.75。对于负相关部分也进行相同的操作。
对于卷积层,权值共享,设a_im为当前层的第i个特征图的第m个神经元,与前面层的K个神经元b_mk相连接(K等于滤波器大小),而这k个b_mk神经元即为卷积核对应的卷积的部分,由卷积的位置m决定。而在第i特征图中的所有的M个神经元a_im(m=1,2,…,M),虽连接前一层的多个不同的神经元b_mk,但都共享同一个权重集。所以这里计算a_im和b_mk之间相关系数的平均值,具体选取方式与连接层类似。
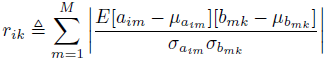
实验
- 分析稀疏对性能的影响:图中“1/256-f”表示对网络层f(参考Baseline model的网络结构图)稀疏程度S设为1/256。因为连接层的参数占较大比例,作者只稀疏了连接层。稀疏压缩后准确率不降反升。

- 相关程度导向的权重选择方法比较:图中“-r”表示完全随机选取;“-h”表示只选取强相关的连接;而默认的是上面提到的选取大部分强相关的,少部分弱相关的神经元连接;

- 是否使用稀疏前的模型进行初始化的效果比较:
