
论文:Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
算法论文主页:http://www.robots.ox.ac.uk/~vgg/research/very_deep
论文概述
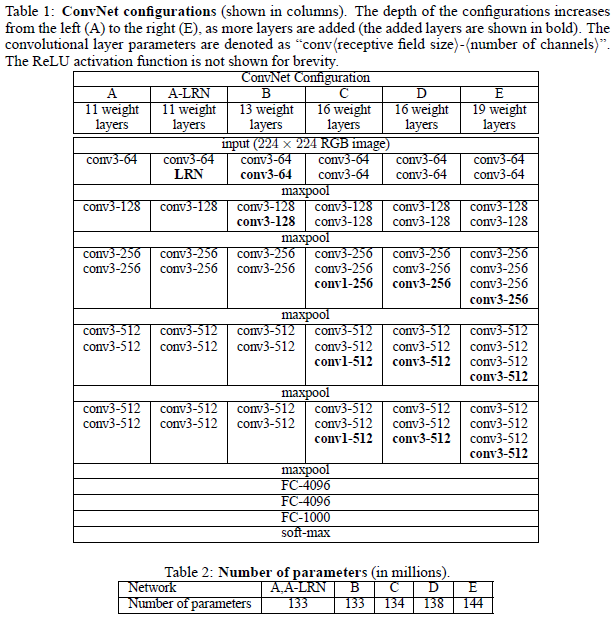
论文主要探索了卷积网络的深度对识别准确率的影响,构建了多个网络进行分析。
数据集
使用的是ILSVRC-2012数据集(被用于ILSVRC 2012到2014的比赛中)。该数据库的图片包含1000类,分为三部分:训练集(1.3M张)、验证集(50K)、测试集(100K),有两个评价标准:top-1和top-5 error,前者是多类分类错误率,被错误分类的图像所占比例;后者是主要的评价标准,为物体实际类别不在top-5的类别内所占的比例。
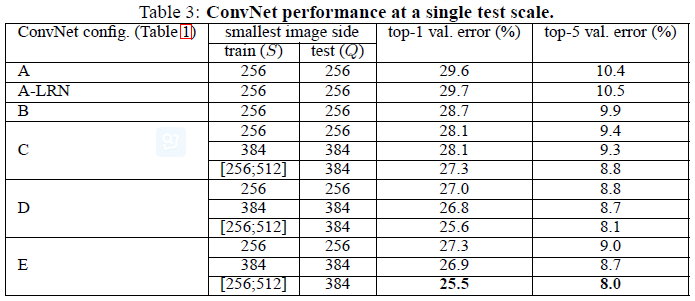
单尺度
-
注意到在没有任何归一化层的模型A中使用local response normalisation (A-LRN network)也并不能起到提升作用,因此也没有在更深的网络(B-E)中使用归一化层。
-
注意到随着卷积层数增加分类误差减少(11层到19层),在这些网络中,层数到19层后错误率达到饱和,但更深的层数可能对更大的数据集有帮助。
-
尽管网络深度一致,但C网络(包含三个11卷积层)比D网络(整个网络都使用33的卷积层)效果差,这意味着尽管额外的非线性层能起到辅助作用,但使用不同感受野的卷积提取空间信息也很重要;一个深的网络使用小的卷积滤波器比浅的网络使用大的卷积滤波器效果要好。
-
训练图像尺度的微小变化[256,512]比使用固定大小的效果好不少,尽管在测试时都是使用固定尺度。这证明使用尺度缩放进行训练数据扩增对于多尺度图像检测有一定作用。
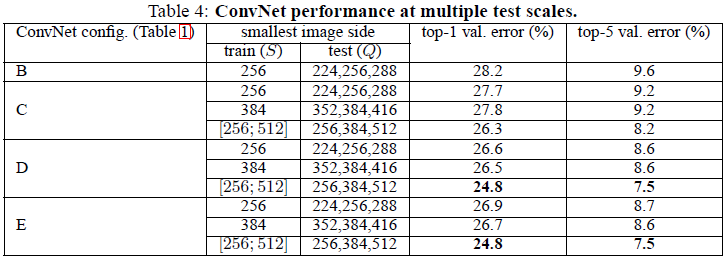
多尺度
表中数据表明在测试时进行scale jittering尺度缩放数据扩增比使用同样的模型而尺度固定的情况效果要好。
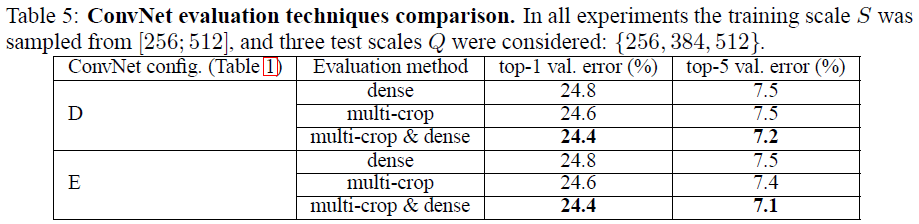
多裁切
multi-corp比dense效果好,且二者有互补的地方。
网络效果比较
