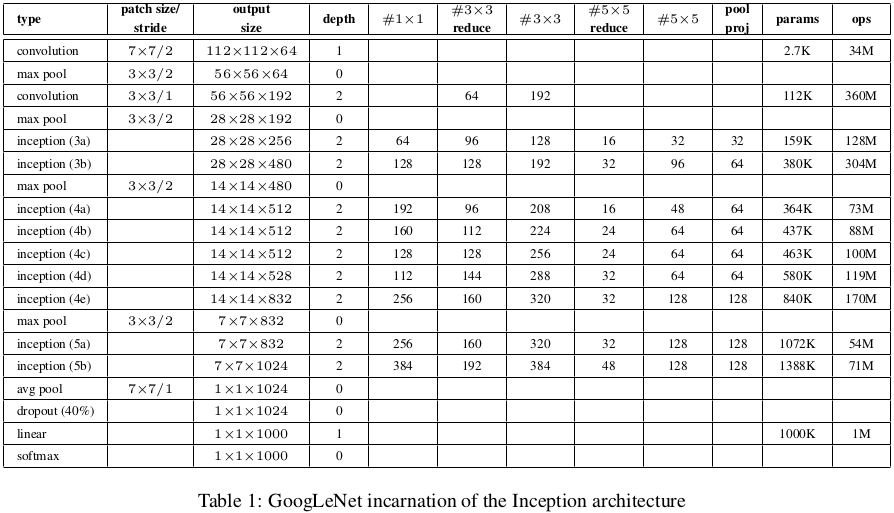
论文:Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[J]. 2015:1-9.
论文算法概述
提出一种深度卷积神经网络框架,叫做Inception。一个典型的应用例子是22层的GoogLeNet,取得ILSVRC14中物体分类与检测冠军。这种框架基于Hebbian规则和多尺度处理的思想进行设计,其主要特点是可以在固定的运算量下提升网络的深度和宽度,使能更好利用网络中的计算资源。且GoogLeNet的参数比2012年的Alexnet少12倍,准确率却高不少。主要采用了1×1卷积的方式,主要用于实现两个功能:1)作为降维模块去除限制网络大小的计算瓶颈; 2)使可以加深加宽网络结构而不降低网络性能。
目的和更高层次的考虑
提高深度网络性能的最直接方式是增加网络复杂度,这增加包括深度(网络层数)和宽度(每层的神经元个数)。但是模型越大意味着参数越多,则越容易产生过拟合,特别是数据量不够的时候;另一个缺点是这样会增加计算资源的使用,例如,在深度网络中,两个卷积层连接在一起,任何的一致的大小增加都会造成参数呈二次方增加。如果增加的是无效的,例如,大部分权重最后会接近于0,这样许多计算就浪费了。尽管主要的目的是提高性能,在实际中计算资源是有限的。
解决上面问题最基本的方法是将最后的全连接层甚至是中间的卷积层改为稀疏连接结构。以往文章表明,如果一个数据集的概率分布能被一个大的稀疏的深度网络所表征,则最优的网络结构能通过激活单元的相关统计构建出来(稀疏网络结构可以重新构建出最优结构),并与Hebbian原则相对应——neurons that fire together, wire together。
从底层考虑,现在的硬件在非一致稀疏数据结构上的计算是很低效的,特别是在这些数据上使用为密集矩阵计算优化过的库函数时。卷积网络为了打破对称性并提高学习率,传统上会在特征维度上使用随机稀疏的方式来实现。而后来又为了更好地实现并行计算,转为使用全连接的方式。
所以,问题是有没有一种方法,既能保证网络结构的稀疏性,又能利用密集矩阵的高计算性能。而文中提出的Inception Module可解决这问题。
结构上的细节
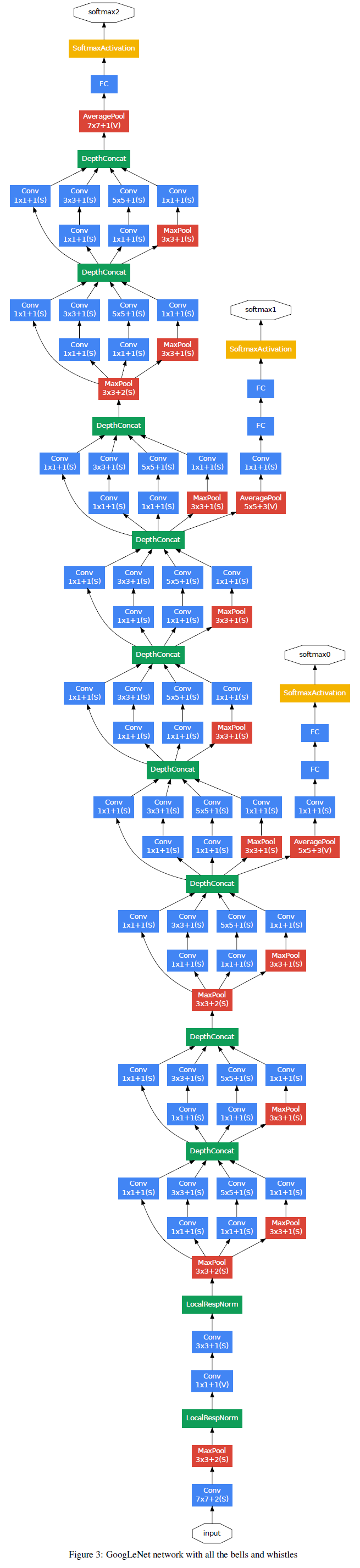
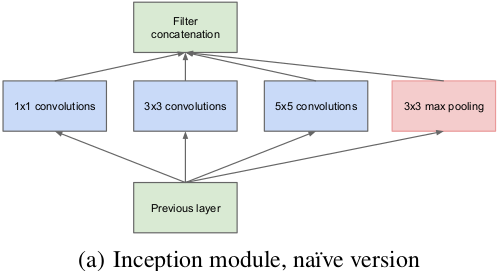
Inception结构的主要目的是在卷积网络中找出一个最优的局部稀疏结构,可以用来近似并代替现有的密集型的组件。我们假定前面层的每个单元都与输入图像的某些区域相关联,并且这些单元组成滤波器组。在低层(靠近输入图像的层)中相关的单元将对应于某局部区域,使用1×1的卷积后仍然对应着该区域,使用3×3则可以得到更大的区域对应。为了避免patch alignment的问题,Inception框架使用的滤波器大小是1×1,3×3,5×5,而这样的设计并不是必须的,更多只是为了方便。而在更高层中进行特征提取,特征的稀疏聚集程度需要增加,即3×3和5×5卷积在更高的层中应有所增加。Inception模块如图所示。
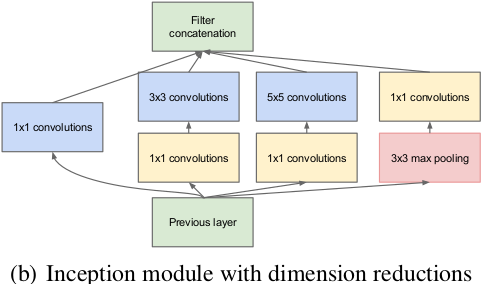
在这些模块中的一个大问题是,在上层卷积层中有很多滤波器导致尽管5×5的卷积数量不多也会产生较多的计算量。除了卷积外,其中的池化单元也存在这个问题。尽管这种结构比较接近最优稀疏结构,但其计算也并不高效,会导致在几层过后计算量暴增。因此提出在计算量会增加较多的地方联合使用降维和预测,在3×3和5×5卷积前面使用1×1卷积进行降维。
对于降维如模块图所示,虽然图a的卷积核都比较小,但是当输入和输出的通道数很大时,乘起来也会使得卷积核参数变的很大,而图b加入1×1卷积后可以降低输入的通道数,卷积核参数、运算复杂度也就跟着下降。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。
这种框架有两个优点,1)可以增加每层网络参数而不会造成计算量暴增;2)可以使同时提取不同尺度的特征。
GoogLeNet