论文: Wu X, He R, Sun Z, et al. A Light CNN for Deep Face Representation with Noisy Labels[J]. Computer Science, 2016.
Github: https://github.com/AlfredXiangWu/face_verification_experiment
论文算法概述
提出一个轻量级的CNN网络结构,可在包含大量噪声的训练样本中训练人脸识别任务。
-
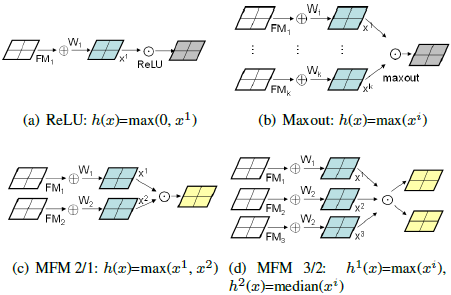
在CNN的每层卷积层中引入了maxout激活概念,得到一个具有少量参数的Max-Feature-Map(MFM)。与ReLU通过阈值或偏置来抑制神经元的做法不同,MFM是通过竞争关系来抑制。不仅可以将噪声信号和有用信号分离开来,还可以在特征选择上起来关键作用。
-
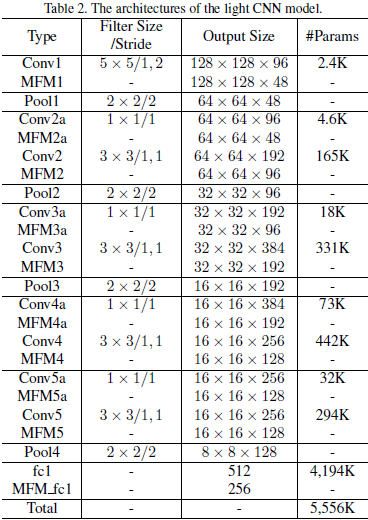
该网络基于MFM,有5个卷积层和4个Network in Network(NIN)层。小的卷积核与NIN是为了减少参数,提升性能。
-
采用通过预训练模型的一种semantic bootstrapping的方法,提高模型在噪声样本中的稳定性。错误样本可以通过预测的概率被检测出来。
-
实验证明该网络可以在包含大量噪声的训练样本中训练轻量级的模型,而单模型输出256维特征向量,在5个人脸测试集上达到state-of-art的效果。且在CPU上速度达到67ms。
Max-Feature-Map Operation
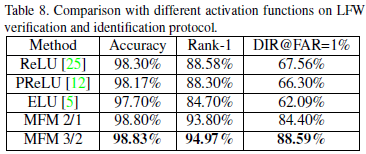
大规模的人脸训练集通常都包含有很多噪声和错误标签,如果这些噪声没有被处理好,模型效果无法达到最优。ReLU激活函数提供了将噪声信号和有用信号分离的方法,利用阈值或偏置去决定一个神经元是否被激活,如果未被激活则输出为0。但是这阈值化可能会导致一些信息的损失,特别在前面的卷积层中,因为这些层与Gabor滤波器类似(正负相应都很重要)。为了缓解这个问题,一些论文中提出了Leaky Rectified Linear Units (LReLU) , Parametric Rectified Linear Units(PReLU) 和Exponential Linear等。而文中则提出了MFM(Max-Feature-Map Operation)。
MFM:

The Light CNN Framework
输入144x144灰度人脸图,随机crop至128x128,进入网络训练。网络结构如下:
Semantic Bootstrapping for Noisy Label
提出了semantic bootstrapping的方法对包含有大量噪声的训练集进行采样,来解决训练集中的噪声问题。首先,直接用带大量噪声的训练集训练出light CNN模型,而MFM操作可能会使在训练过程中感知一致性的性质变得鲁棒,因为由MFM得到的梯度是稀疏的。因此light CNN模型在很多噪声样本的情况下依然能稳定收敛;第二,使用得到的light CNN模型去预测带噪声的训练样本,并设置一个阈值将真实样本和噪声样本区分开来;最后在调整后的样本集中重新训练模型。
实验
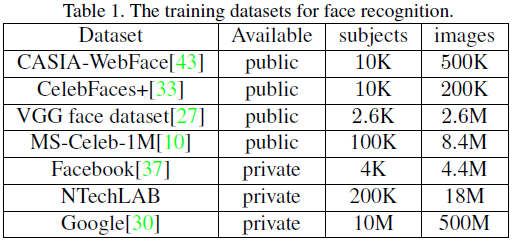
实验中采用了CASIA-WebFace和MS-Celeb-1M人脸数据库进行训练,所以图片都转成灰度图并通过5个特征点对齐成144x144大小,并随机crop至128x128进入网络。对齐方式是使双眼中心点连线水平,双眼中点和嘴巴中点距离在训练时为48个像素,在测试时为40个像素?。通过过余弦相似度进行特征匹配。