
论文: Wu X, He R, Sun Z, et al. A Light CNN for Deep Face Representation with Noisy Labels[J]. Computer Science, 2016.
论文算法概述
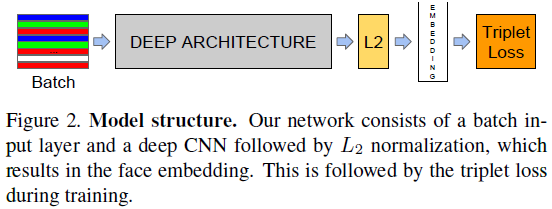
提出一个用于人脸验证、人脸识别和聚类问题的框架。该方法利于深度卷积网络去训练为每张图片提取其Euclidean embedding,训练完成后,在embedding space中可以直接使用squared L2 distances去表示两个人脸的相似度。
其他使用深度网络人脸识别方法大多利用softmax分类层来进行身份的监督训练,然后取中间层输出作为身份特征。但因为希望训练出来的模型能够很好地应用的新的人脸图像中,这样以分类问题处理并不够直接;并且为充分表达每张人脸图像,其特征向量一般会很长,导致算法效率低。为提高效率,也有人使用PCA对特征向量进行降维,但PCA是线性变换,添加一个网络层即可较容易地学习出来。
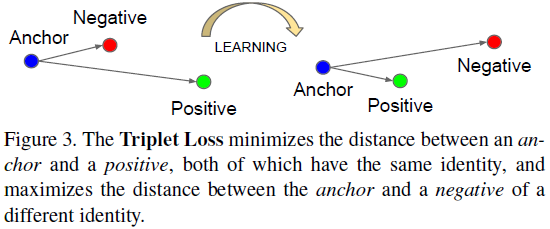
而该论文中的FaceNet输出的是128维特征,使用基于LMNN的triplet based loss function进行训练。triplet loss如下figure所示,直接地反映了人脸验证识别所要达到的目标。这triplets包括两个匹配的face thumbnails和一个不匹配的face thumbnails,而thumbnails指的是紧贴着人脸区域的图像块,只需要尺度和平移变换,而不需要2D或3D对齐。
Triplet Loss
以f(x)表示编码过程,将图像x映射到d维的欧式空间上,限制f(x)的L2范数为1,所以Triplet Loss如下式子,训练使L最小化。其中a/p/n分别对应anchor/positive/negative,alpha是强制的类间间隔。

Triplet Selection
少量样本即可产生大量的Triplets,但大部分Triplets对网络贡献并不大,如果将所有可能的Triplets都用于训练,会导致收敛速度很慢。所以需要合理选取Triplets,在给定anchor,希望找到的positive与其距离较远(hard positive),找到的negative与其距离较近(hard negative)。但这样选取Triplets时,不太可能将整个训练集都计算一下每对样本的距离,而且选取过程中很容易选到噪声样本,因为噪声样本较容易满足这些要求。
所以文中给出了两种选取方法来解决这些问题:1、在线下每N步生成一次Triplets,使用训练过程中最近保存得到的模型在样本子集中计算距离;2、在线上每个mini-batch中生成。
实验中使用线上生成的方式,对训练样本进行采样使每个mini-batch中的每个身份都有约40张人脸图像,然后随机选取一些不匹配的人脸样本加入到该mini-batch中。使用mini-batch中所有的anchor-positive对,并选择其对应的hard negative。这里没有必要去一一比较每个anchor-positive对来找到hard anchor-positive对,因为实验发现使用全部anchor-positive对去训练,收敛也很快。
同时也会结合采用线下生成的方式,获取一些semi-hard的样本对,这里的semi-hard是指忽略掉Triplet Loss目标函数中的alpha后得到的样本对。
Deep Convolutional Networks
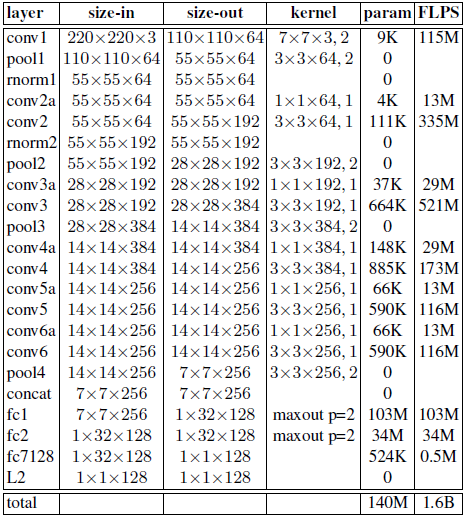
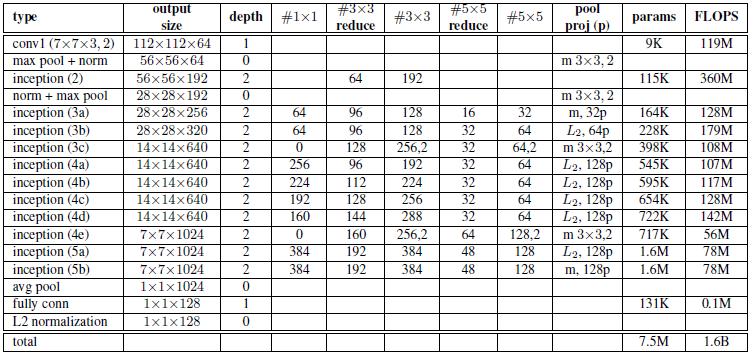
如下左为基于ZF网络设计的模型,命名为NN1,右图为基于Inception结构的NN2。
实验
在LFW上将人脸图像进行固定的中心裁剪,人脸验证准确率为98.87%;如果使用人脸对齐后再输入实验,则为99.63%。


