
论文: Taigman Y, Yang M, Ranzato M, et al. DeepFace: Closing the Gap to Human-Level Performance in Face Verification[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014:1701-1708.
论文算法概述
如传统的人脸识别流程是检测--对齐--特征表示--分类。这里主要考虑对齐和特征表示步骤,采用显式的3D人脸模型做变换对齐,使用一个9层的网络模型做特征表示。该网络包含1亿2千万个参数,有多个权重不共享的局部连接层。训练集包含4百万图像,超过4000个身份。在LFW上结果是97.35%。
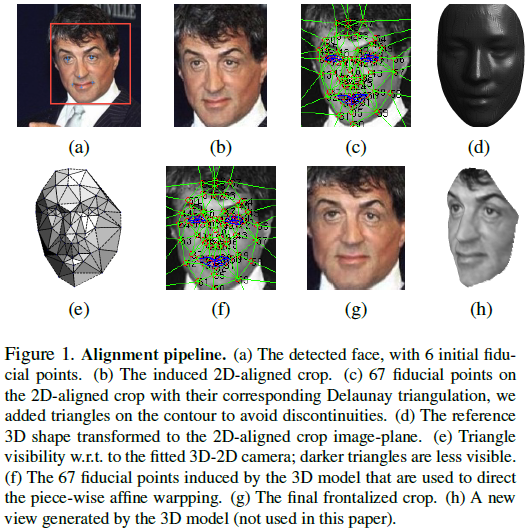
对齐
特征表示
网络设计如图2所示,以RGB3通道图像输入,前面三层提取低层次特征。其中极大值池化M2使卷积输出对偏移更具鲁棒性,但太多池化会导致图像信息丢失,所以整个网络只在第一层卷积后使用极大值池化。
第三层后面接着三个局部卷积层(L4/L5/L6),局部卷积中有滤波器的界限,每个区域上采用不同的滤波器集,参数不共享。采用局部卷积的原因如下:
-
因为对齐图像中不同区域具有不同的局部信息,卷积的空间稳定性的假设不成立,例如,在对齐的情况下,人脸五官都分布在特定区域,而眼睛和眉毛具有不同的外观,鼻子和嘴巴也有非常明显的区别,若采用同一组滤波器会造成信息丢失;
-
局部卷积层仅加重了训练的参数数量,并不会影响特征提取的运算量;
-
局部卷积层因为权重不共享,因此需要较大量的训练数据,而本文的的数据量可以满足这个条件。
然后接上两个全连接层(F7/F8),用于获取图像不同区域的特征之间的相关性,其中F7为特征表达层。最后为F7输出的4096维特征进行归一化以减小亮度的影响,先将每个维度的数值除以整个训练集中该维度对应的最大值,然后进行L2归一化。
