论文: Ledig C, Theis L, Huszar F, et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J]. 2016.
论文模型: https://twitter.box.com/s/lcue6vlrd01ljkdtdkhmfvk7vtjhetog
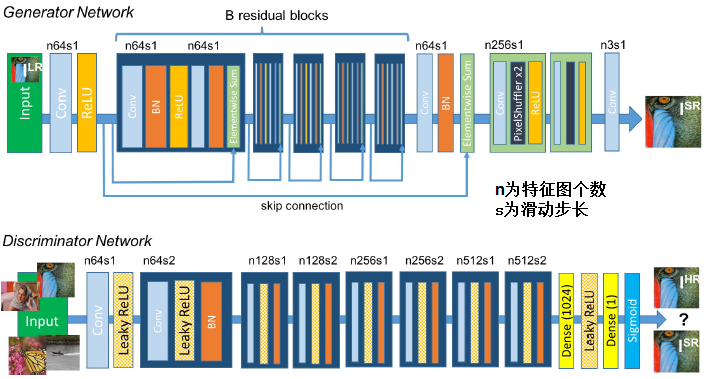
论文算法概述
论文中,使用生成对抗网络GAN用于超分辨率重构。提出了一种感知损失(perceptual loss),包含有对抗损失和内容损失(content loss)。对抗损失基于鉴别器使生成图像更接近真实图像;内容损失由直观相似性(perceptual similarity)驱动而不是像素域上的相似性。文中以深度残差网络作为生成模型,以VGG网络作为鉴别器,可以从高度下采样的图像中恢复图像真实的纹理信息。大量的mean-opinion-score(MOS,平均主观意见分)测试表明使用SRGAN在视觉质量(perceptual quality)上有巨大意义。
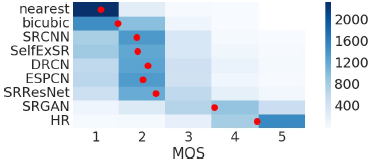
对于大的上采样因子,SR通常存在纹理细节缺失的问题,如图中SRResNet的PSNR评分很高,但从服饰/叶子等可以看出,也存在细节缺失的问题。而文中提出的算法SRGAN虽然PSNR分数没有SRResNet的高,但可生成很多细节信息,使在人类视觉感官上图像质量更高。注:论中算法评价标准为MOS,而不是PSNR或SSIM。

论文主要贡献:1、提出了一个以MSE为优化目标的SRResNet,刷新了4倍上采样的PSNR和SSIM的记录。2、提出采用以GAN为基础的感知损失(perceptual loss)的SRGAN模型,将由VGG的特征图计算得到的loss替换基于MSE的content loss,该loss在像素空间上更不易被改变。3、在4倍上采样中,在三个公共数据集中进行MOS测试证明,SRGAN达到最优效果。
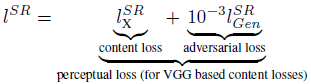
Content loss
基于像素的MSE loss计算公式如下,该公式被很多state-of-the-art的SR算法广泛使用作为优化目标,能达到很高的PSNR值,但存在高频细节内容缺失的问题。
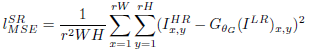
所以文中定义了基于ImageNet中19层VGG预训练模型的ReLU激活层的VGG loss。以Phi-i,j表示在第i层极大池化层之前的第j卷积层(激活函数后)中获得的特征图,定义VGG loss作为欧式距离度量重构图G(I-LR)与标签图I-HR的距离,如下式子。其中W-i,j和H-i,j表示VGG网络中对应各自特征图的维度。

Adversarial loss:

训练细节与实验结果
从ImageNet中随机抽取35w样本,通过双立方插值进行4倍下采样。从不同的16张图像上随机裁剪96x96的图像块作为一个mini-batch。基于MSE优化的SRResNet作为GAN的生成器初始化预训练模型以避免陷入局部最优,交替训练。在测试的时候将batch-normalization的更新关掉,使输出仅取决与输入。