
论文: Shrivastava A, Pfister T, Tuzel O, et al. Learning from Simulated and Unsupervised Images through Adversarial Training[J]. 2016.
译文推荐: http://weixin.niurenqushi.com/article/2016-12-28/4734786.html
论文算法概述
人工合成的图像和真实图像分布存在一定差异,所以直接从人工合成样本中进行训练难以达到预期的效果。为减少这个差异,论文中提出Simulated+Unsupervised (S+U) learning“模拟+无监督”学习方法,在保留从网络输出的注释信息的同时使用无标签的真实数据使simulator生成数据更接近现实。这种方法与GANs生成对抗网络相似,但这里是以合成图像作为输入,而不是GAN中的以随机向量作为输入。相对于标准的GAN,有几点关键的修改:自正则化(self-regularization),局部对抗性损失和使用精炼图像refined images去优化鉴别器。该方法在没有使用任何标注数据的情况下在MPIIGaze数据库上达到最高水平的效果。
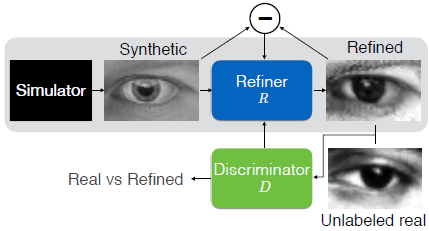
上图为SimGAN的概要图,使用一个refiner网络R来对由模拟器simulator生成的图像进行精炼(refine),使最小化局部对抗损失(local adversarial loss)和自正则化(self regularization)。其中对抗损失迷惑用于判断图像是真实图像还是精炼图像的鉴别器D,而自正则化用于最小化生成图像和精炼图像的差异。这样保留了注释信息(如图中的视线方向),使精炼得到的图像适合于模型训练。在训练时,精炼网络R和鉴别器网络D是交替更新的。
模拟+无监督学习
S+U学习的目的是使用无标签真实图像集去训练精炼网络R去提炼由模拟器网络得到的图像,在保留生成网络中该图像的注释信息的同时,使精炼图像看起来更像真实图像。精炼网络R的参数theta,由两个loss进行监督训练,其中xi为训练样本,xi~为相应的精炼图像,第一部分是在合成图像中增加真实性的成本,第二部分是通过最小化合成图像与精炼图像的差异来保留注释信息的成本。
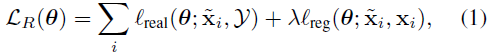
带自正则化的对抗损失
为了增加合成图像的真实性,需要在合成图像分布和真实图像的分布之间建立联系。一个理想的精炼器会使精炼图像和真实图像无法以高置信度被准确分类,这就需要一个与之对抗的鉴别器,被训练用于区分精炼图像和真实图像。利用GAN的方法,让精炼器和鉴别器二者之间进行极限博弈,训练时交替地进行更新。鉴别其的损失函数如下式:
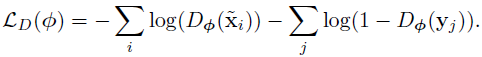
相当于二分类交叉熵误差,Dφ(x)为输入图像是合成图像的概率,1-Dφ(x)为真实图像的概率。Dφ(x)由一个卷积网络得到,该网络最后一层输出是一输入样本为精炼图像的概率,使用SDG进行二分类训练。1式中的真实性损失lreal基于鉴别器D为:
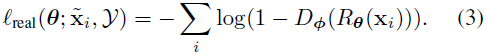
为了最小化这个loss,精炼器迫使鉴别器将精炼图像误分类为真实图像。除了生成逼真的图像外,精炼器应保留模拟器simulator的注释信息,如眼睛凝视视线估计,学习到的转换应不改变凝视的方向,或者如手部姿态估计,各手部节点的位置不应该改变。为实现这个,提出自正则化,目的是最小化合成图像和精炼图像的差异,该损失函数如下,其中R是全卷积网络,步长为1无池化。这在像素级上改变了合成图像,保留了图像的全局结构和注释信息,而不是像全连接网络那样修改整体图像的内容。通过交替地使精炼器和鉴别器损失函数最小化来训练,固定一个更新一个。
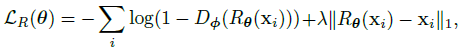
局部对抗损失
精炼网络的另一个关键点是它应在不引入任何人工生成的信息的前提下学习真实图像的特征,当我们训练单个强鉴别网络时,精炼网络会倾向于过度强调特定的图像特征去迷惑当前的鉴别器网络,从而导致衍生出一些人工产物。通过观察得到,任何从精炼图像中采样得到的图像块都应该有着与真实图像块一致的数据分布,因此与其设定一个全局鉴别器网络,还不如根据对每个局部的图像块进行单独分类来设定鉴别器。该论文中使用全卷积网络来实现,如下图3,wh是图像局部块的数量,在训练精炼器网络时,将wh个局部块的交叉熵相累加。
根据精炼图像的历史情况去更新鉴别器
对抗训练的另一个问题是鉴别器只关注最后的精炼图像结果进行训练,这样会导致有两个问题,一个是分散了对抗训练,二是精炼器会再次引入鉴别器曾经关注过而当前没关注的人工合成信息。在训练过程中的任何时刻从精炼器中得到的精炼图像,对于鉴别器来说都属于‘假’的一类,所以鉴别器应可以把这些图像都分到‘假’一类,而不仅只针对当前生成的mini-batch个精炼图像。通过简单修改Algorithm1,使采用精炼器的历史情况来更新鉴别器。令B为由以往精炼器生成的精炼图像集的缓存,b为mini-batch大小,在鉴别器训练的每次迭代中,通过从当前精炼器中采样b/2的图像来计算鉴别器的损失函数,然后从缓存中采样额外的b/2的图像来更新参数。保持缓存B大小固定,然后在每次迭代中随机使用新生成的精炼图像去替换缓存中b/2个图像,如图4。

实验结果
