
论文: Goodfellow I, Pougetabadie J, Mirza M, et al. Generative Adversarial Nets[J]. Advances in Neural Information Processing Systems, 2014:2672-2680.
Github: http://www.github.com/goodfeli/adversarial
译文推荐:
-
对抗样本知识点概述: http://www.lancezhange.com/2015/11/19/adversarial-samples/
-
对抗样本的八个误解与事实: http://www.kdnuggets.com/2015/07/deep-learning-adversarial-examples-misconceptions.html ; http://m.csdn.net/article_pt.html?arcid=2825248
-
其他:
论文算法概述
提出通过一个对抗过程来评估生成模型,在对抗的过程中同时训练两个网络,一个是生成模型G用于获取数据的分布情况,另一个是区分模型D用于判断一个样本是来自训练集还是由模型G生成。训练中D目标是最大化地将原始训练样本和由G生成的样本准确区分,即二分类问题,最大化log D(x);G则要最大化模型D出现评估错误的概率log(1 – D(G(z))),而GAN模型没有损失函数,优化过程是一个“二元极小极大博弈(minimax two-player game)”问题。则最后达到最优解时,G可以再现训练样本的分布,而D的判断准确率为50%。
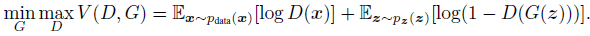
模型G和D使用多层感知器来构建,所以只需使用BP算法即可训练而不需要用到马尔科夫链和其他近似推理网络。可实现给定一批样本,通过无监督训练一个网络,能够生成类似的新样本。

优缺点
优:
-
计算量小,不需要使用马尔科夫链反复采样,也不用在学习中推论(如wake-sleep),只需要使用BP来计算梯度,并且大量的函数可以被包含到模型中。
-
具有一些统计上的优势,因为生成网络的参数是由样本通过梯度传播来训练的,而并不是由样本直接拷贝而来。
-
对抗网络生成的样本更锐利清晰,甚至对于退化的分布也一样。而基于马尔科夫链的方法需要提供有点模糊的分布以便链能够混合各种分辨率?
缺: 由模型G得到的数据分布没有一个明确的表示,没有损失函数,在过于自由不可控,训练过程中很难区分是否在向好的方向训练。而且在训练时模型D需要和模型G同步得很好,否则可能发生崩溃问题,生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。训练较困难。

结论与展望
-
一个条件生成模型p(x c)可以由将c作为输入添加到模型G和D中得到。 -
学习近似推理可以通过训练辅助网络来基于x预测z,这是类似于用wake-sleep算法训练的推理网络,但该推理网络具有的优势是在训练完毕后能一个固定的生成器。
-
半监督学习:来自判别模型D或推论网络的特征在带标签数据有限的情况下有助于提升分类器的性能。
- 效率提升:通过更好的协调G和D或者在训练中采用更好的分布去采样z能够对训练起到加速作用。