论文: A-Fast-RCNN : Hard Positive Generation via Adversary for Object Detection
Github: https://github.com/xiaolonw/adversarial-frcnn
论文算法概述
为了使检测器对遮挡和形变具有一定的不变性,一般用的是数据驱动的方式进行模型训练。但这些遮挡和形变的样本在整个训练集中的比例很小,服从long-tail分布,部分情况会更稀缺,也太不可能会涵盖所有情况。所以文中方案是训练一个对抗网络来生成一些难以被检测器准确分类的遮挡和形变样本,生成的方式是通过掩盖空间上的部分特征图得到遮挡图片或对特征响应作修改生成空间上的形变。而这想法的关键点在于在卷积特征空间生成对抗样本而不是直接生成像素.对抗网络的监督信号是softmax,学习用来预测会使检测器检测错误的特征。因此,如果从对抗网络上得到的特征很容易被检测器正确分类,那该特征在对抗网络上会有较大的loss。
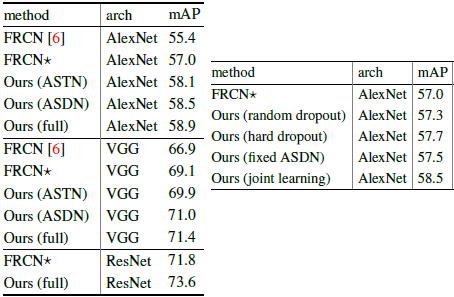
这里基于Fast RCNN实验,与原版Fast RCNN相比,在VOC2007上mAP提高2.3%,在VOC2012上提高2.6%。
Adversarial Spatial Dropout for Occlusion
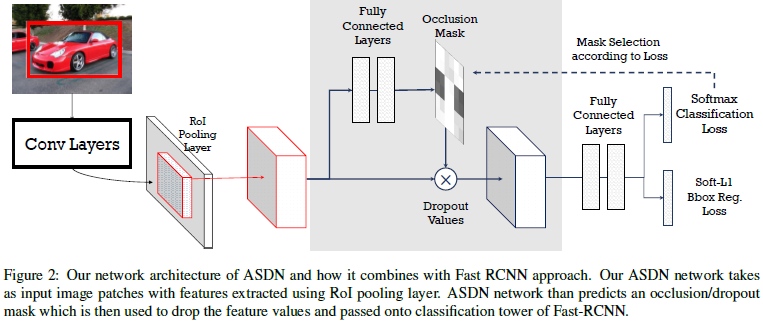
提出了Adversarial Spatial Dropout Network(ASDN)在前景目标的深度特征上生成遮挡掩膜。把ROI池化后得到的基于区域的特征作为对抗网络的输入,给定一个物体的特征图,ASDN会尝试生成一个mask表示该部分特征被置空后检测器无法准确检测到该物体。例如,给定一个目标提取到特征X,维度是d x d x c,d为空间上的尺度,c为通道数,ASDN会预测一个d x d的mask M,并阈值化为0和1,当M_ij为0时,则特征图上所有通道的(i,j)位置均置为0。
Network Architecture:Fast RCNN由ImageNet预训练模型进行初始化,而对抗网络则共享fast RCNN中的卷积层和ROI池化层(只是结构不含权重),然后接上自己的全连接层。注意,两个网络进行对抗训练,网络权重不共享。
Model Pre-training:在实验中发现,在使用ASDN去提升Fast-RCNN之前,以生成occlusions 为目的去预训练ASDN很重要。在这里采用阶段性训练的方式,首先不含ASDN去训练Fast-RCNN,等Fast-RCNN有一定效果时,开始训练ASDN模型去生成occlusions。
Initializing ASDN Network:为了初始化ASDN模型,给定一个d x d的特征图X,在上面使用一个d/3 x d/3的滑动窗口,如图3(a)。每到一个滑动位置将对应所有通道的值屏蔽掉,生成该区域的一个新的特征向量,然后该特征向量通过分类层去计算loss。将每个滑动窗口,各自屏蔽自己的部分后得到的各个对应特征向量后,都计算loss,选择最高的loss,以该loss对应的窗口为基准,生成一个d x d的mask。为n个正样本候选框生成这些mask,得到n对用于ASDN的训练样本。主要的思想是让ASDN学会去生成这些能让检测器具有较大loss的mask。ASDN的监督信号为二值化的交叉熵函数:
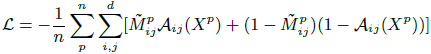
式中A_ij(X)为给定特征图X时ASDN在坐标i,j上的输出,在训练时使用该loss函数迭代10K次后,可以看到这网络可以判断图像上哪部分对分类器的影响大,如图3(b)所示。

Thresholding by Sampling:ASDN的输出并不是二值化的mask,更像是连续的热力图。这里采用的阈值化方式是截取最高的1/3像素,或者选取最高的1/2然后随机排除1/2中的1/3,以保持多样性和随机性。
Joint Learning:给定预训练的ASDN和Fast-RCNN模型后,在每次迭代中联合两个模型进行训练。为训练Fast-RCNN检测器,先使用ASDN去生成mask,采样阈值化后应用到前向过程中ROI池化后的特征图上。然后以修改过的特征进行现象传播。特征被修改了,但标签还是一样的,这样相当于生成了更困难更多样化的训练样本。为训练ASDN,因为使用了采样的策略去将热力图转化为二值mask,转化后,结果不可微,所以不能将分类器的loss直接反向传播。所以文中采用的方式是,计算哪个mask对分类影响较大,然后使用这些困难的mask作为标签去直接去训练ASDN,loss使用的是Initializing ASDN Network中提到的二值化交叉熵。
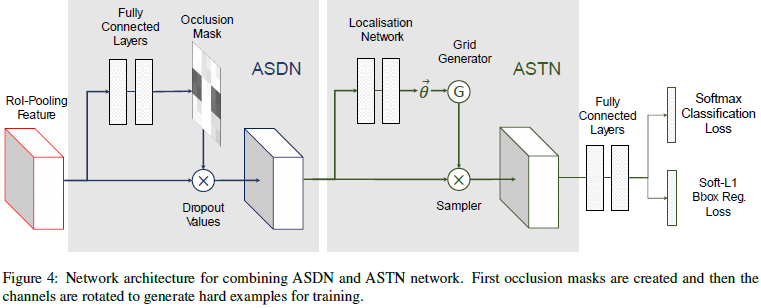
Adversarial Spatial Transformer Network
STN Overview:STN有三个组成部分:定位网络localisation network,栅格生成器grid generator和采样器sampler。给定特征图作为输入,localisation network会为这些形变估计变量(如旋转角度,平移距离和缩放因子等)。这些变量都会被用于作为grid generator和sampler的输入运用在特征图上,输出则为形变的特征图。注意这里只需要训练localisation network的参数。STN的一个主要贡献是使整个过程可微分,因此localisation network可以通过反向传播直接去优化分类器。细节参考论文《Spatial transformer networks》.NIPS2015。
Adversarial STN:在这里的ASTN,主要关注点是特征图的旋转。给定一个经过ROI池化后的特征图作为输入,ASTN会学习去旋转特征图使其更难以被识别。localisation network包含三个全连接层,前面两层由ImageNet的fc6和fc7的预训练参数作为初始值。联合训练ASTN和Fast-RCNN检测器,训练检测器的过程与ASDN中的相似。经过ROI池化后的特征由ASTN进行转换,然后前向传播到更高层去计算softmax损失。ASTN的训练目标是使检测器混淆产生误检,而ASTN的训练与ASDN不同的是,ASTN的空间变换是可微分的,可以直接使用分类的loss去反向传播微调ASTN中的localisation network的参数。
Implementation Details:在实验中,限制由ASTN产生的旋转角度范围在顺逆时针旋转的10度以内,且并非把全部特征图都旋转到同一方向,而是将特征图基于通道维度分成4块并为每块估计4个不同的角度。因为每个通道对应着一种特征的激活情况,各自旋转通道对应着将物体的旋转各个部分,则会造成形变。作者也发现,如果把所有特征图都旋转同一个角度,ASTN会经常预测得到最大的角度。而如果旋转的是四个角度而不是一个,这样任务的复杂度就高了,会抑制网络预测一些不重要的形变。
Adversarial Fusion
两个对抗网络ASDN和ASTN可以合并在一起在同一个检测框架中进行训练,各自提供不同的信息,通过两个网络的同时对抗使检测器更具鲁棒性。这里将这两个网络以连续的方式合并到Fast-RCNN中,如图4所示。从ROI池化后提取到的特征图输入到ASDN中屏蔽掉部分神经元,然后把新的特征图再送入ASTN做形变。
Experiments
在VOC2007上的结果如下图所示,与Online Hard Example Mining(OHEM)相比,在VOC2007上文中结果(71.4%)比OHEM(69.9%)要好,但在VOC2012上文中结果(69.0%)比OHEM(69.8%)要稍低一点。作者认为这两种方法可以互补,实验中将两种方法联合,在VOC2012上可以达到71.7%;而两个OHEM模型联合为71.2%,两个文中的模型联合则为70.2%。