
论文: Jeong J, Park H, Kwak N. Enhancement of SSD by concatenating feature maps for object detection[J]. 2017.
论文算法概述
如题,通过拼接用于目标检测的特征图来增强SSD。对于传统SSD有两个问题:1)在特征金字塔中的每一层都单独作为分类器的输入,因此同一个目标会在多个尺度上被检测到。考虑到一个较低层的特征图上的一个具体位置被激活了,那么更高层的对应位置很大机率也会被激活。然而SSD中并没有考虑不同尺度之间的关系,因为在每个尺度上,只关注了一个网络层。2)SSD对小目标检测效果不好。在这篇论文中,通过以下两步来处理这些问题,一是分类器的实现会考虑特征金字塔内层之间的关系,第二则是高效地增加网络层中的通道数。文中提出的网络框架,在分类网络中对不同尺度很适合共享权重,所以只需要一个单一的分类网络即可。此外该单一的分类网络对于小目标检测较为有效。在传统的SSD中,如果在一个确定尺度下没有目标,则分类网络对这个尺度会学不到任何内容。而如果使用文中提出的单一的分类网络,则可以在不同尺度下从训练样本中获取目标信息。总之,R-SSD可以防止对一个目标检出多个框,另外里面通道数能够高效地增加去检测小目标。
Method
如图3展示了三种方法,为分类网络在不同层上增加特征图数量,以利用特征金字塔中不同层之间的关系,这三种方法都可以进行端到端训练。如图3(a),较低层的特征图通过池化串接到较高层上。在这种方式中,分类网络会有大的感受野可以丰富特征表达能力;如图3(b),则通过反卷积或上采样将较高层串接到较低层上;图3(c)中,特征串联的方法则同时应用在较低层的池化和较高层的反卷积中。需要注意的是,在串联特征图之前,必须要先进行归一化,因为在不同层级上的特征值的尺度是不一样的,而论文中使用的归一化方法是batch normalization。
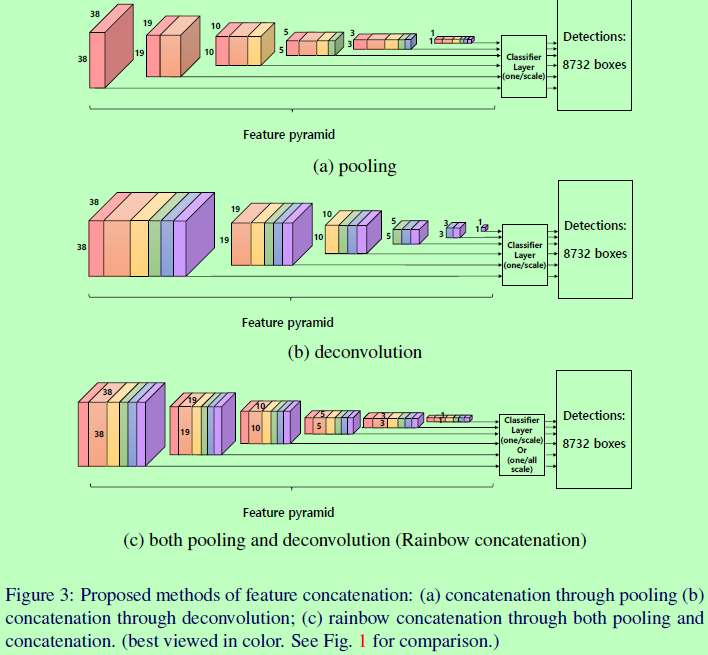
Concatenation through pooling or deconvolution
在SSD的结构中,一般来说,较低层级的通道数会比较高层的多。为了明确特征金字塔内层之间的关系和有效率地增加通道数,我们通过池化将特征图串联到较高层上或通过反卷积串联到较低层上。在DSSD中,使用的是包含有3个卷积层、1个反卷积层、3个批归一化层、2个Relu和按位乘积层的反卷积模块。而这里提出的与DSSD的不同,这里的特征串联只通过带批归一化的反卷积,而不需要按位相乘。图3(a)和(b)这些结构的优点是在做检测时,有效的信息可以取自其他层。但也有一个缺点,那就是信息流是单向的,如3(a)是从左到右串联,3(b)是从右到左串联,则分类器无法利用其他方向的信息,所以就有了3(c)的Rainbow concatenation。
Rainbow concatenation
如图3(c)为rainbow concatenation,同时使用池化和反卷积去生成特征图。每一层在池化或反卷积特征到相同大小后,将其串联在一起。特征金字塔内每一层都包含2816个特征图(即总共串联了512、1024、512、256、256、256)。因为现在特征金字塔内每一层都有相同数量的特征图,那么对于不同的分类网络层的权重是可以共享的,即只需要一个分类网络即可(如图3a和b结构的classify layer是每个尺度一个,具体可见SSD的网络结构设置),且default boxes等也可以共享参数,如下表1。

Experiments
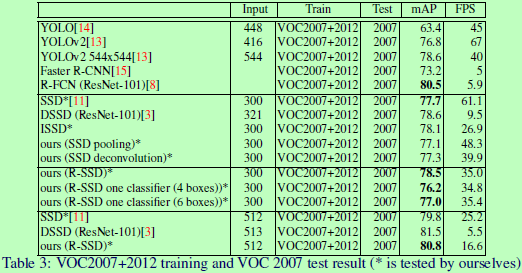
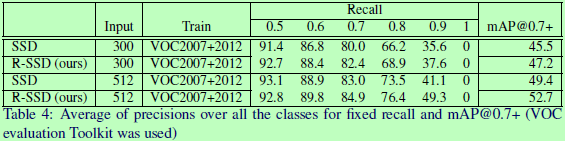

总结
通过关联不同层的同时高效地增加网络层中的通道数来对SSD优化。其中关联不同层并增加通道数的方式主要有:1)将较低层的特征图通过池化串接到较高层上;2)通过反卷积或上采样将较高层串接到较低层上。但这两种处理方式下的信息流是单向的,如1是从左到右串联,2是从右到左串联,则分类器无法利用其他方向的信息。
所以R-SSD中同时使用了1和2,即同时使用从低层到高层的池化和从高层到低层的反卷积去生成特征图。