
论文: Wang Y, Ji X, Zhou Z, et al. Detecting Faces Using Region-based Fully Convolutional Networks[J]. 2017.
论文算法概述
如题,使用R-FCN做人脸检测。引入了一种对位置敏感的均值池化(position sensitive average pooling)来调整评分图score maps的响应,消除每个脸部部分不均匀分布的影响。在目前WiderFace和FDDB上达榜首。

R-FCN Based Architecture
基于R-FCN,以ResNet作为骨干。为了更好检测小人脸,引入更多小尺度的anchors。此外,为对位置敏感的ROI池化(position sensitive RoI pooling)设置更小的池化尺度以减少多余信息,同时改善投票规则(均值池化),作为该论文提出的对位置敏感的均值池化(position sensitive average pooling)。最后在ResNet的最后阶段使用atrous卷积(带孔卷积,在论文deeplabcv2中提出)去保持特征图的尺度而不丢失上下文信息。
Position-Sensitive Average Pooling
原始R-FCN中,在position-sensitive RoI pooling后使用了全局均值池化去整合特征到单一维度。这个操作会导致人脸的每个位置对检测都会有一样的贡献。然而实际对于人脸检测来说,人脸的每个区域的贡献是不一样的。例如,根据人脸识别的实验中,眼睛会更受关注。直观地,我们相信人脸的不同位置对人脸检测的重要程度是不一样的。因此,我们提出对位置敏感的RoI池化输出的每个区域执行加权平均,以重新调整该区域的权重,这个操作命名为position-sensitive average pooling。
从公式上说,令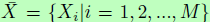 表示位置敏感的ROI池化层输出的M个特征图,
表示位置敏感的ROI池化层输出的M个特征图, 表示第i个特征图,其中N表示池化特征图的大小。位置敏感的均值池化计算特征响应的加权均值,以得到池化特征:
表示第i个特征图,其中N表示池化特征图的大小。位置敏感的均值池化计算特征响应的加权均值,以得到池化特征: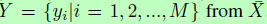 ,其中y_i表示为:
,其中y_i表示为:
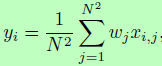
其中w_j表示第j个位置的权重。注意,位置敏感的均值池化可以被认为是在特征响应的每个位置上嵌入特征并随后接一个均值池化。因此,在大多数深度学习框架上实现这位置敏感的均值池化是很方便的。
Multi-Scale Training and Testing
使用多尺度训练和测试策略来提高性能。在训练阶段,将输入图像较短的一段缩放到1024或1200个像素,同时在负样本上使用On-line Hard Example Mining (OHEM),并使每个mini-batch上正负样本比例为1:3。在测试阶段,为每个测试图像构建图像金字塔,金字塔内每个尺度都单独测试,最后将不同尺度的结果合并在一起作为最终结果。
Experiments
-
FDDB: False positive 2000时,离散0.9942,连续0.7595。
-
WiderFace:mAP值,Val = 0.947 / 0.935 / 0.874 - easy / medium / hard; Test = 0.943 / 0.931 / 0.876 - easy / medium / hard。
总结
在RFCN的PSROI池化后的全局均值池化改成对位置敏感的均值池化。因为作者认为PSROI池化后接全局均值池化去整合特征到单一维度会导致人脸的每个位置对检测都会有一样的贡献,而实际上人脸每个区域贡献是不同的,如眼镜部分可能会更受关注。
对位置敏感的均值池化:将PSROI池化后的特征图切分成多个区域,每个区域赋予一个权重,以加权均值代替全局均值。