
论文: DetNet: A Backbone network for Object Detection
论文算法概述
基于CNN的目标检测器大多直接使用基于imagenet的预训练分类模型进行微调,作为骨干(backbone)特征提取网络。而这篇论文提出的DetNet是一个为目标检测而设计的主干网络。DetNet包含的额外的stages与传统的用于图像分类的骨干网络不一样,用于分类的网络需要通过下采样来得到较大的感受野,而DetNet则仍然能在深的网络层上保留高分辨率,高分辨率有有助于目标定位。
Motivation
最近的目标检测器通常都需要一个预训练在ImageNet上分类任务的骨干网络。而检测任务和分类任务不同,检测任务不仅需要对目标分类,还要对目标进行定位。但用于分类的网络如VGG16和ResNet并不适合用于目标定位,其特征图的分辨率会逐渐减小。一些方法,如FPN和膨胀等被应用到这些网络上去保持空间分辨率,然而在训练这些主干网络时,仍然会存在以下三个问题:
-
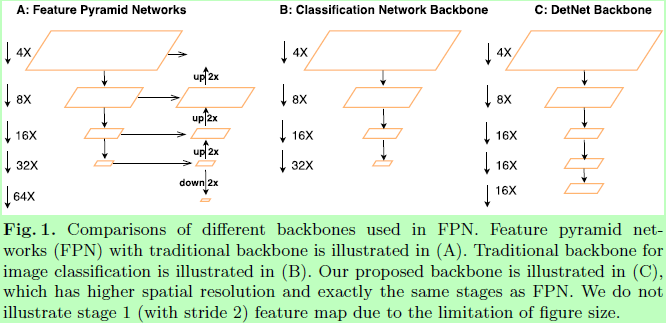
The number of network stages is different.。如图1B所示,典型的分类网络涉及5个stages,每个stage通过2x池化或步长为2的卷积对特征图进行下采样。因此输出特征图的空间大小是32倍下采样的。与传统的分类网络不同,特征金字塔检测器FPN通常采用更多stages。例如,在FPN上添加额外的stage P6去处理更大的目标,在RetinaNet上以类似的方式添加P6和P7。显然,额外的stage如P6是没有在ImageNet数据集上预训练过的。
-
Weak visibility of large objects.特征图带有较强的语义信息,相对于输入图像的步长是32,这会带来很大的有效感受野,有助于ImageNet的分类任务。然而,大的感受野并不利于目标定位。在FPN中,生成大目标并在更深的层进行预测,这些目标的边界位置会变得较模糊,导致结果难以准确回归。当更多stages加入到分类网络中时,会进行更多的下采样,那么这种情况会变得更差。
-
Weak visibility of large objects。大的滑动步长还会导致小目标丢失。随着特征图的空间分辨率下降,小目标的信息会弱化,而添加了更多的上下文信息。所以FPN选择在浅层预测小目标。然而浅层的语义信息不多,难以识别目标的类别。因此检测器必须从更深的层上加入增加高级表达的上下文信息,来增加其分类能力。如图1A所示,FPN采用的方法是添加bottom-up pathway。但是小物体很可能在更深的层里直接就消失了。
为了解决这些问题,提出的DetNet有以下特点:1、stages的数量是直接为目标检测设计的,而额外的stages如P6可以由ImageNet数据集预训练;2、尽管比传统的分类网络添加更多stages,但仍能在保持大的感受野下保持特征图的分辨率。
DetNet Design
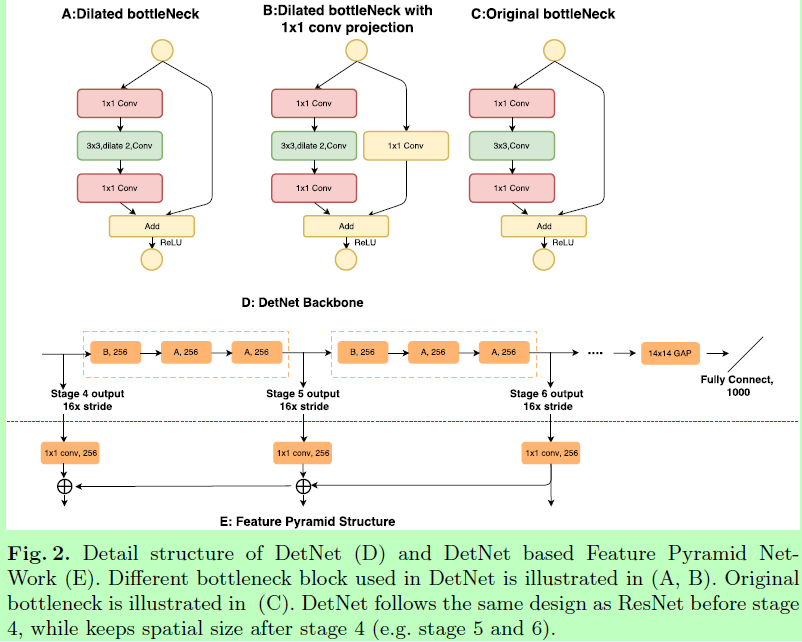
采用ResNet-50作为基础模型,结构如图2所示,设计细节如下:
-
在骨干上引入额外的stages P6,这将会在最后用于目标检测,像FPN那样。同时,在stage4后把空间分辨率固定在16倍降采样。
-
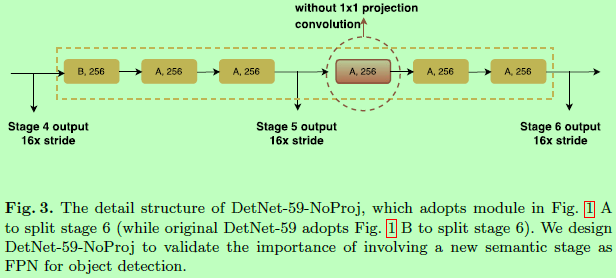
因为在stage4后的空间分辨率固定了,为了引入新的stage,在每个stage的开始采用一个带1x1卷积映射的dilated bottleneck,如图2B所示。而实验证明这对像FPN那样的multi-stage检测器很重要。
-
采用带膨胀的bottleneck作为网络的基本模块去扩大感受野。因为膨胀卷积还是比较消耗时间的,所以我们的stage5和stage6保持与stage4同样的通道数(bottleneck block的256个输入通道数)。与传统的骨干设计不同,后者会在随后的stage将通道数翻倍。
将DetNet与任何使用或不使用特征金字塔的检测器结合在一起使用是很容易的。在不失代表性的前提下,使用了优秀的FPN检测起作为baselines去验证DetNet的有效性。因为DetNet仅改变FPN的骨干(backbone),所以我们将FPN中除了骨干外的其他结构固定。也因为我们不需要减少ResNet-50的stage 4后面的空间分辨率大小,所以这里只是简单地从上到下地将这些stages的输出相加。
Experiments
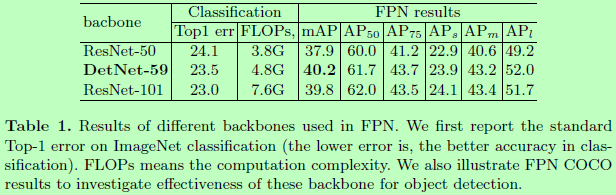
在FPN检测器中,采用DetNet作为骨干的比采用ResNet的mAP要高,但计算复杂度也相对高一些:
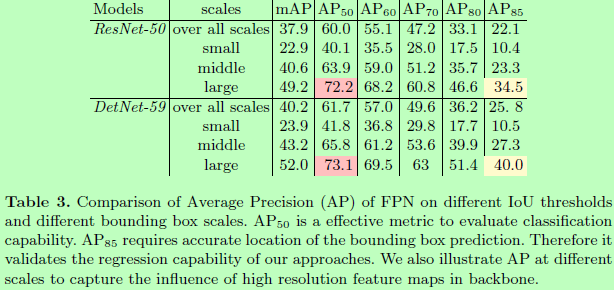
对于是否采用1x1的projection卷积(可看回图2B)的实验如下:

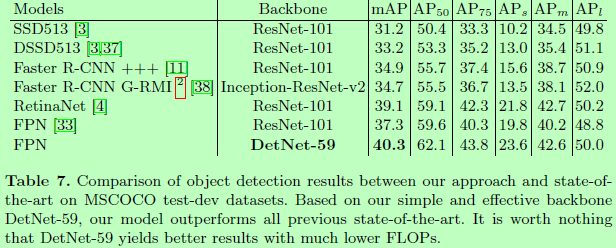
与其他检测器的比较:
总结
与原始分类模型的骨干网络比,DetNet的不同点主要在几个方面:
-
降采样到一定程度后不再降采样,而会维持尺度去堆叠网络;
-
采用带1x1卷积映射的膨胀bottleneck(类似残差,一条分支为1x1卷积,另一条则头尾是1x1卷积,中间夹这其他卷积)作为基本模块,其中的膨胀卷积能扩大感受野。
总之,该结构能在保持空间分辨率的同时扩大感受野。
PS:1、还是需要预训练模型的,但只要预训练模型的一部分;2、直接使用分类的预训练模型时降采样过多会导致小目标缺失,大目标边界模糊。