
论文: Fu C Y, Liu W, Ranga A, et al. DSSD : Deconvolutional Single Shot Detector[J]. 2017.
论文算法概述
SSD中各层之间的信息没有充分交互,且底层大分辨率特征图的特征表达能力弱,使小目标检测效果不好。主要通过引入额外的上下文信息去进行优化,结构如下图1所示。实验结果:VOC07为81.5%mAP,VOC12为80.0% ,MS COCO为33.3%。

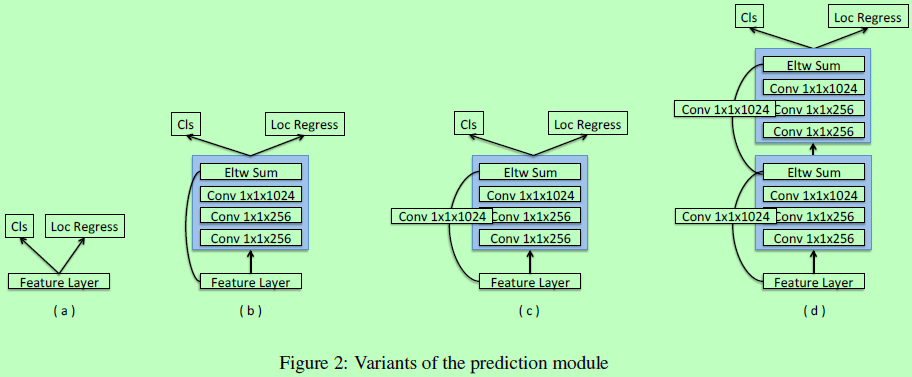
Prediction module
在原始SSD中,目标函数是直接使用在被选择的特征图接一个L2归一化层上的(这个L2归一化层接在conv4_3,用于处理梯度量级很大的问题)。即原始SSD的无预测模块如下图2(a)所示,作者也尝试了图2中的b、c、d三种预测模块,发现使用Residual-101加预测模块会比使用VGG而不带预测模块的在处理高分辨率图像方面会好很多。
Deconvolutional SSD
如上图1底部所示,额外的反卷积层相继地增加特征图的分辨率。为了使特征得到加强,采用由hourglass模型中参考而来的“skip connection”。hourglass模型在编码和解码阶段含有对称的层,而这里使解码部分网络改成很浅,原因主要有两个:1、速度问题;2、缺少包含有解码部分的预训练模型,因为分类任务给的是一个全图的标签,而不像检测任务那样的局部标签。
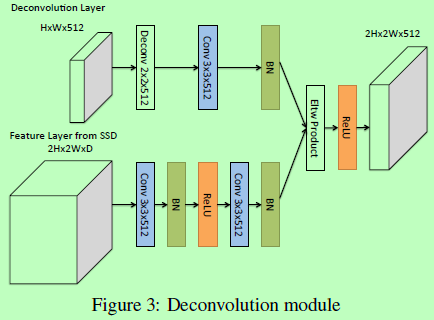
Deconvolution Module
为了辅助整合前面特征图和反卷积层的信息,作者引入了一个如下图3所示的反卷积模块(上面图1中的圆圈)。首先,在每个卷积层后面都接一个BN层,然后使用训练好的反卷积层替代双线程插值上采样,最后使用element-wise product进行整合。
Training
训练方法与SSD基本一样。首先需要将一系列default boxes与目标GT boxes相互匹配。对于每个GT boxes,将具有最大重叠度的和任何重叠度超过阈值的default boxes与之匹配。在剩下未匹配上的default boxes中,基于置信度去选择一定数量的作为附样本,使比例为3:1。然后联合最小化位置loss和置信度loss,即smooth L1和softmax loss。因为这里SSD并不像Faster RCNN那样具有特征或像素的重采样阶段,那样的重采样需要依赖大量的数据扩增(随机裁剪、随机光度失真和随机翻转),所以这里并不太过依赖数据扩增,但添加一些随机的扩增也是有助于提高检测效果的。
在prior box方面,相对原始SSD有一点小改动。在原始SSD中,boxes 的高宽比例是2或3。这里在训练boxes上用k均值聚类,以方框区域的平方根作为特征,以两个簇心开始,如果误差可减少20%以上,则增加簇的数量,作者实验最终可收敛到7个簇心。因为SSD框架将输入resize成正方形,而多数训练图像都是较宽的,所以输出框都较高。统计得到大多数box的高宽比都在1-3范围内,所以作者加多了一个比例1.6,即使用1.6、2.0和3.0。
Experiments
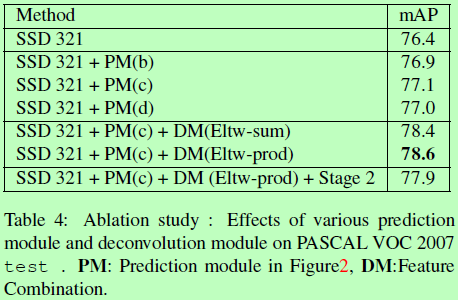

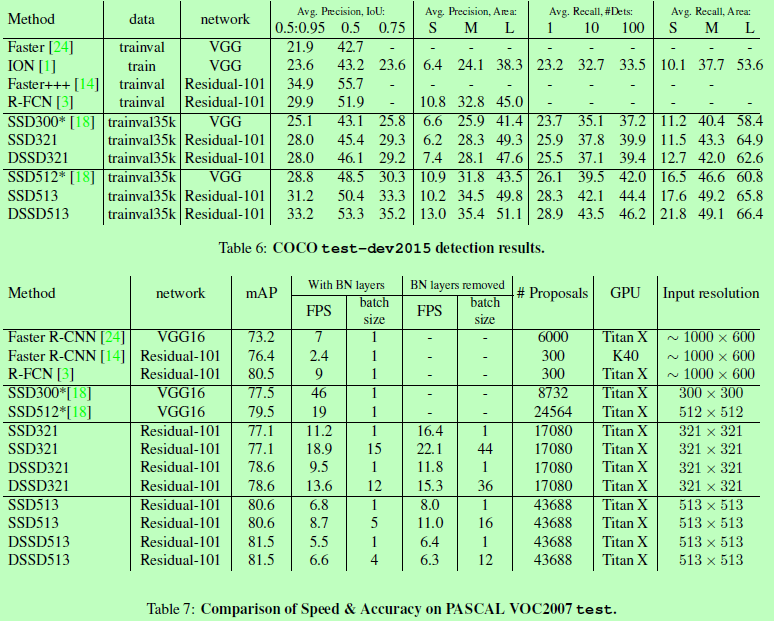
总结
在SSD的基础上添加的上下文信息,让不同分辨的层之间的特征交互更充分,也提高了主要用于检测小目标的低层高分辨率特征图的特征表达能力,即同时兼顾了高层的语义信息和低层的空间分辨率。
具体是在末端添加一系列的反卷积模块,与前面未反卷积部分层一一对应,呈沙漏状,连接情况与FPN类似。前面一层卷积和后面一层反卷积做BN并以点积方式相连接后进入检测器,检测对应尺度的目标。