
论文: Light-Head R-CNN: In Defense of Two-Stage Object Detector
论文算法概述
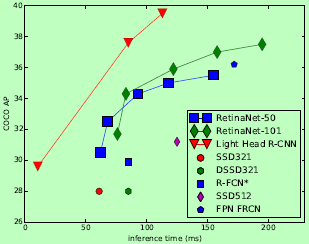
一种two-stage检测器。two-stage中可将任务分为两步:body用于生成proposals;head(backbone network)用于对proposals分类。而在Faster RCNN和R_FCN中为达到较好的准确率,其head是heavy的,使速度慢准确率高。文中算法设计重点在light-head,使用了一个大核的可分离卷积(Separable Convolutions,参考论文《Xception Deep Learning with Depthwise Separable Convolutions》)去生成通道数少的小特征图,随后接一个提取分类和回归的特征表示的RCNN子网络,该子网络仅包含一个池化层和一个全连接层。
R-CNN subnet
Faster R-CNN使用强大的R-CNN作为其stage2的分类器,使准确率高,但其计算量大,特别是在proposals的数量多时。为了给RoI-wise subnet加速,R-FCN首先为每个region生成一系列的score maps,其通道数量为classes x p x p(p是紧接后面的池化大小),然后对每个ROI进行池化,平均投票最终预测结果。因为使用了没太多计算量的R-CNN subnet,R-FCN中计算重点放在了RoI shared score maps的生成过程上去取得较好的结果。即Faster R-CNN和R-FCN都有一个heavy head,只是在网络的不同地方而已。
从准确率的角度看,尽管Faster R-CNN擅长与对ROI的分类,但为了减少第一个全连接层的计算量,它通常会使用到全局均值池化,这样会有损空间信息;而对于R-FCN,它直接对position-sensitive pooling后的预测结果进行池化。在没有RoI-wise计算层的情况下,而其效果通常会比Faster R-CNN差。
从速度的角度看,Faster R-CNN对每个ROI都单独运行一次耗时R-CNN子网络,使速度慢;在R-FCN中使用了低成本的R-CNN作为第二阶段的检测器,但R-FCN需要为ROI池化生成一个很大的评分图,因此仍然很耗时间和内存。
对于以上问题,这里的Light-Head RCNN,使用一个小的低成本的全连接层作为这里的R-CNN子网络,如图2(C)为Light-Head RCNN的大体结构图。并使RoI warping(如RoI池化)之前输入的特征图数量较少,因为作者发现将ROI池化层应用在thin feature maps上不仅可以减少计算量,还可以避免Faster-RCNN中全局池化的精度影响。
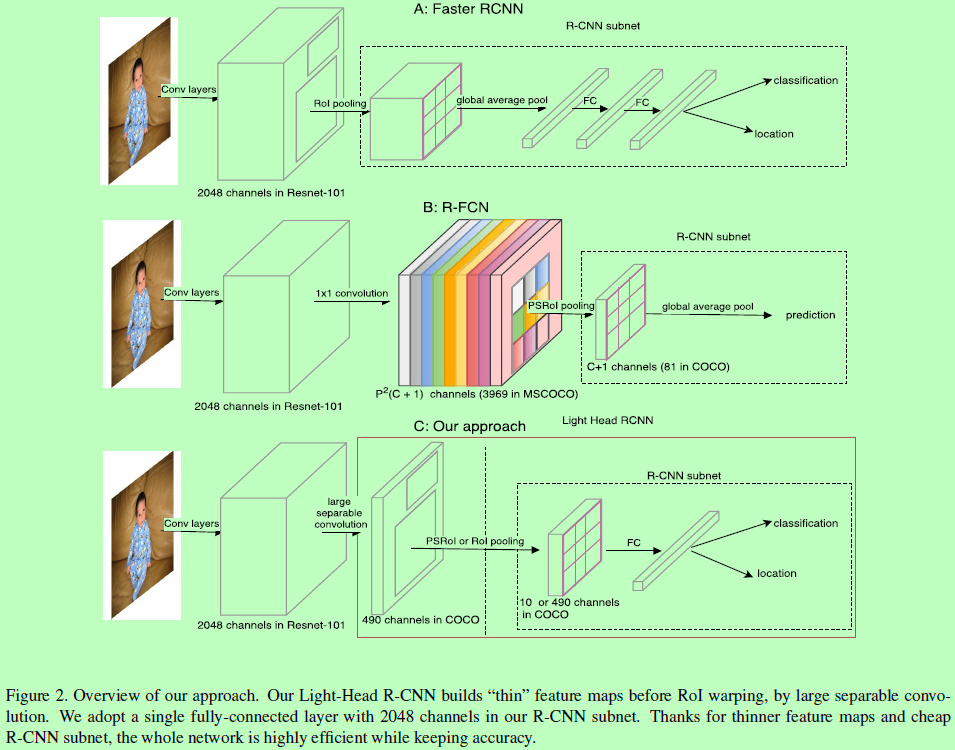
Light-Head RCNN for Object Detection
Basic feature extractor:为验证算法性能(配置标示为L),采用的是ResNet101;为验证算法效率(配置标示为S),则采用与Xception类似的小网络。其中图2中“Conv layers”表示的就是这个基础模型。
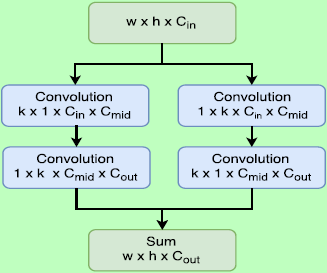
Thin feature maps.:采用了大的可分离卷积层,结构如下。文中令k=15,对于配置S其C_mid=16,对于L其C_mid=256。将C_out限制在10 x p x p,而不是像R-FCN中的classes x p x p。
R-CNN subnet + RPN。
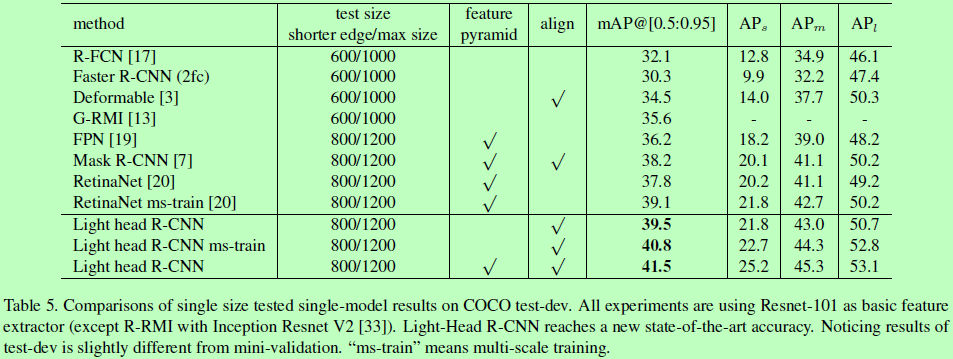
Experiments

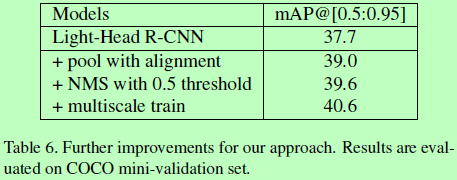
总结
在Faster RCNN基础上进行优化的一种两阶段检测器,在body(生成proposal部分)末尾添加大核的可分离卷积以提取一个通道数少而感受野大的特征图,head(处理每个proposal)部分则只对ROI池化或PSROI的结果通过一个FC层后做分类和回归。侧重点在head是轻量级的,且作者发现在通道数少的特征图上做ROI池化,既可节省资源还能提高准确率。