
论文: Zhang S, Zhu X, Lei Z, et al. S3FD: Single Shot Scale-invariant Face Detector[J]. 2017.
Github:https://github.com/sfzhang15/SFD
论文算法概述
一种基于anchors的重点处理尺度问题的人脸检测算法S3FD,在Pascal架构的Titan X上对VGA图像达36FPS。
论文贡献:
-
提出一种不受尺度影响的人脸检测框架有效处理各种尺度的人脸,将anchors铺置大范围的layers上以确保各种尺度的人脸都能提取到足够的特征;
-
通过一种尺度补偿的anchor匹配策略来提高小人脸的召回率;
-
通过一种max-out背景标签来减低小人脸的FPR(false positive rate)。
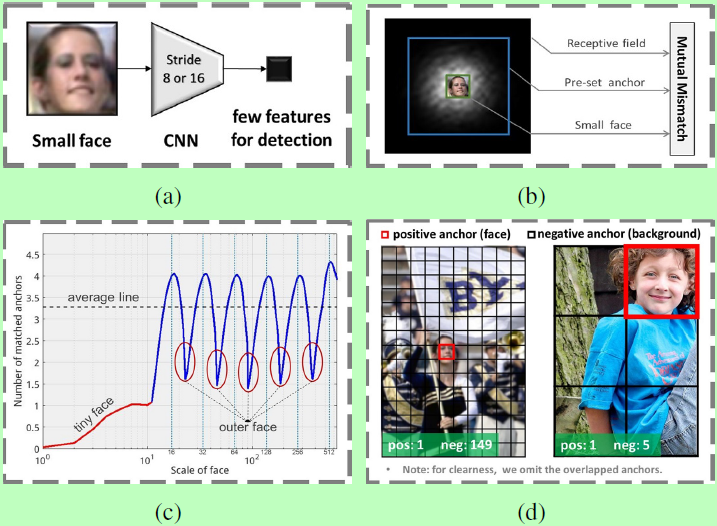
一般基于anchor的检测算法鲁棒性较高,但对小目标的检测效果却较差。结合图1分析,问题的原因主要有一下几点:
-
Few features:网络到检测层时,步长stride很大,小人脸图像块经过大步长的采样后,只能留下了很少的特征;
-
Mismatch:anchors与感受野大小不匹配,并且对于小人脸来说anchors都太大了;
-
Anchor matching strategy:anchors的尺度是离散的(SFD中采用的是16/32/64/128/256/512),但人脸的尺度是非离散的。因此,那些与anchor尺度相差较大的部分尺度的人脸(outer-face)无法匹配到足够的anchors,如下图c;
-
Background from small anchors:下图d右边检测大人脸,全图铺遍anchors共6个,则产生了1个pos和5个neg。而左边铺遍小anchors共150个去检测小人脸,则产生了1个pos和149个neg。即检测小人脸时,小的anchors会带来大量只框住背景的负样本,正负样本极度不均衡。
Scale-equitable framework
网络结构如下图2所示。Base Convolutional Layers为基于VGG16的conv1_1到pool5,而Extra Convolutional Layers则逐步下采样获取多尺度特征图。基于不同尺度选取6个层作为检测层,每个检测层后面带一个p x 3 x 3 x q的卷积层,p和q分别是输入和输出通道数。

Designing scales for anchors
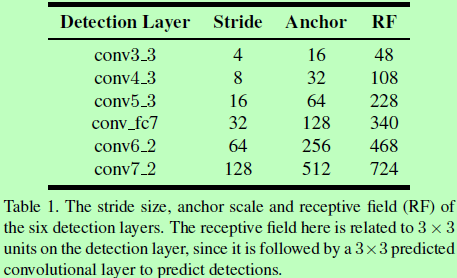
选取的6个检测层都分别与一个特定尺度的anchor相对应,如table1所示。因此检测的目标是人脸,所以anchor的长宽比为1:1。
设计anchor尺度的依据有两个:
-
Effective receptive field:在CNN中有两种感受野,一种是理论感受野,是指输入区域在理论上会被影响到的区域,但是在理论感受野上并不是每个像素对输出的贡献都是平等的。一般来说,中心部分像素的影响会更大,如图3a所示,中心这部分区域为有效感受野。因此anchor应比理论感受野小很多与有效感受野相匹配,如图3b。
-
Equal-proportion interval principle:同等比例间距原则,如上表1所示,anchor的尺度都设为步长4倍,则以保证每个尺度的anchor在图像上都有相同的密度。因为如步长为4,即图像缩小了4倍,然后对应的anchor放大4倍,可以使不同尺度的人脸都能匹配到差不多数量的anchors。

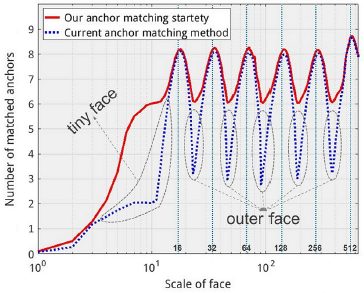
Scale compensation anchor matching strategy
按以往anchor匹配方法会有一个问题:anchor的尺度范围是离散度(一个个尺度大小的集合),而人脸的尺度范围是非离散的,在上面论文概述中有提及。
作者这里的处理方式是:
-
将重叠度阈值由0.5降低到0.35,使增加整体匹配到的anchor数量;
-
将与一人脸的jaccard重叠度高于0.1的所有anchors进行排序,选取top-N(N为成功匹配的anchors的平均数量)。
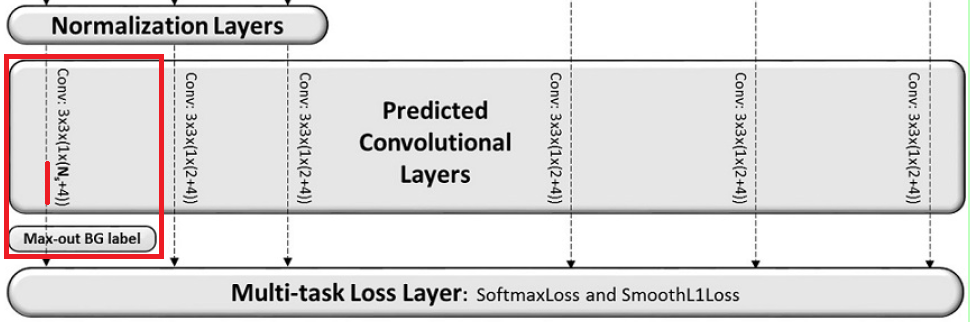
Maxout background label
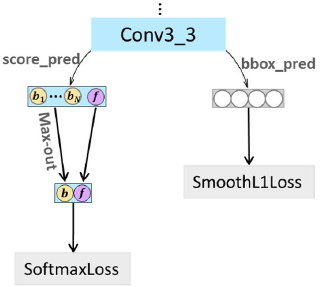
这里提出的方法处理的是上面论文概述中的第4点,即正负样本不均衡的问题。将max-out background label应用在conv3_3上,对于每个对应背景的小anchor,作者在分类中使用预测分数最高的anchor进行梯度的回传(如图在score_pred中从N个背景anchor中只取一个参与训练,前景anchor不变),大大的减少了正负样本不平衡的现象。具体如下图所示:
Experiments
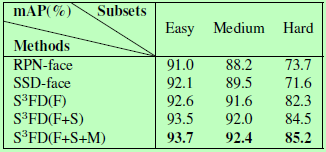
文中几个技巧在widerface验证集上的测试效果,其中F(scale-equitable framework)、S(scale compensation anchor matching strategy)、M(max-out background label):
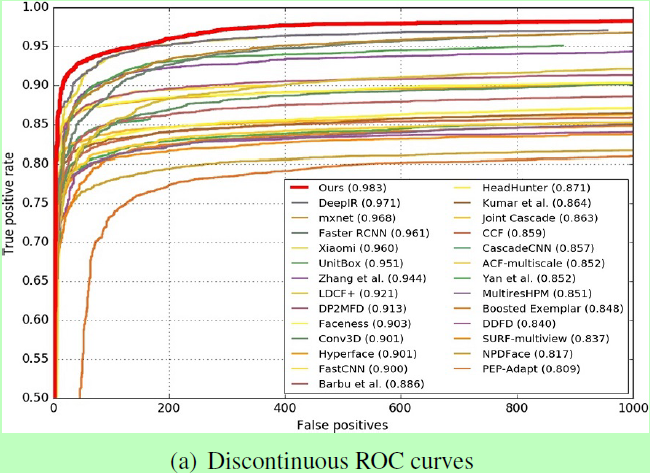
FDDB测试结果:
总结
网络结构上与FaceBoxes/SSD相似,为多尺度检测主要优化了anchor部分:
-
取多个不同尺度的层作为检测层的单阶检测器,而每个检测层对应一个尺度的anchor。
-
将重叠度阈值降低以增加anchor数量,再对特定人脸对应的anchor按重叠度进行排序选一定数量参与训练。这样可以缓解anchor的尺度范围离散的问题。
-
使用了Maxout background label来处理正负anchor不均衡的问题,即多个背景anchor中只取一个评分最大的参与训练(与前景anchor一起)。