
论文: Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[J]. 2017.
推荐博客:https://zhuanlan.zhihu.com/p/28873248
论文算法概述
物体检测主要有两大类:1、two-stage检测器,如Faster RCNN,需要region proposal作为前提,准确率高但速度慢; 2、one-stage检测器,如YOLO、SSD,简单快速但准确率相对较低;
作者认为one-stage检测器准确率低是因为其在训练时前景和背景两类样本极度不均衡导致的。对于two-stage检测器基于region proposal,如Selective Search、EdgeBoxes、DeepMask、RPN等会将大大减少候选目标(约至1~2k),排除掉大部分的背景样本,同时在second stage中,例如固定前景背景比例(1:3)、使用online hard example mining(OHEM)都能使前景背景比例容易控制。相反,对于one-stage检测器通过全图直接生成大量候选目标(~100k),虽然也可以采用类似的启发式采样方法,但极易被分类的背景样本仍占主导,会导致训练低效,以往一般会使用bootstrapping或hard example mining解决该问题。
为了更好处理该问题,作者提出的解决方案是使用focal loss代替标准的cross entropy loss,该loss其实是一个dynamically scaled cross entropy loss,其中在正确类别的置信度提高同时,缩放因子会衰减至0,即会逐渐减少容易样本的贡献,专注于少量的困难样本。能使one-stage检测器在有较快速度的前提下具有超过当前所有two-stage检测器的准确率。作者还设计了一个使用该loss的one-stage检测器,RetinaNet进行实验。

Focal Loss定义
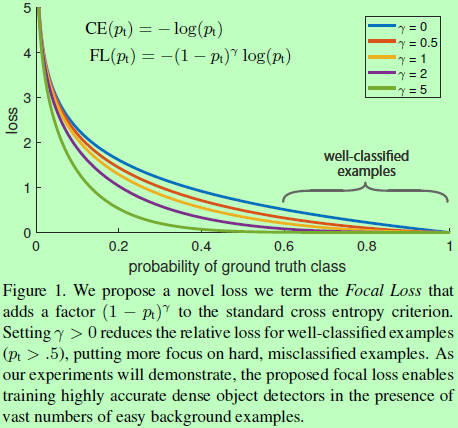
交叉熵CE损失用于二分类的公式为: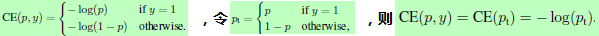 ,其性能如图1最上面蓝线所示,当样本均衡时,效果较好,但容易样本过多时,那些小的loss仍会压制困难样本的训练。对于交叉熵损失中类别不均衡的问题一般的做法是引入一个权重因子alpha,以alpha作为类别1的系数,1-alpha则会另一类系数,公式为
,其性能如图1最上面蓝线所示,当样本均衡时,效果较好,但容易样本过多时,那些小的loss仍会压制困难样本的训练。对于交叉熵损失中类别不均衡的问题一般的做法是引入一个权重因子alpha,以alpha作为类别1的系数,1-alpha则会另一类系数,公式为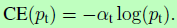 。在实践中,alpha可以通过调转类别的频率进行设置,也可以当成超参数由交叉验证进行设置。
。在实践中,alpha可以通过调转类别的频率进行设置,也可以当成超参数由交叉验证进行设置。
引入权重因子可以平衡正负样本数量,但对简单/困难样本比例并没起到作用。所以作者提出的一个可调整的权重因子加入到交叉熵函数中: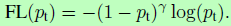 ,其中gamma>=0。当目标被误分类时,pt很小,则权重因子接近1,loss不受影响。而pt往1增大时,对应的是易分样本,权重因子减少至0,loss减小。Gamma用于调整易分样本的下降速率,当gamma=0,FL会退化为CE(实验中gamma=2取得最好效果)。实际应用时,加一个alpha参数进行调节,为
,其中gamma>=0。当目标被误分类时,pt很小,则权重因子接近1,loss不受影响。而pt往1增大时,对应的是易分样本,权重因子减少至0,loss减小。Gamma用于调整易分样本的下降速率,当gamma=0,FL会退化为CE(实验中gamma=2取得最好效果)。实际应用时,加一个alpha参数进行调节,为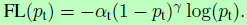 。
。
Class Imbalance
-
Model Initialization:二分类模型默认是初始化为两类具有相同的输出概率,在这样的初始化下,如果类别样本不均衡,出现频率高的类别样本就会主导着整体的loss,造成早期训练的不稳定。为了解决这个问题,作者提出“优先”的概念(对应上面focal loss定义),在训练初期,令模型对样本少的类别的估计p很低,如0.01。这样的改变在模型的初始化而非在loss函数,作者发现这有助于在类别很不均衡时提高训练的稳定性,对于交叉熵和focal loss都有效。
-
Two-stage Detectors:二阶检测器通常使用交叉熵损失进行训练,而没有使用alpha进行平衡或者使用focal loss。对于类别不均衡,常采用two-stage cascade或biased minibatch sampling来处理。第一阶段是一个object proposal机制,将物体候选区域大大减少至一两千个,更重要的是proposals的选择并不是随机的,而是与物体实际标签位置相关,能够去除大量的easy negatives。第二阶段,通常使用biased sampling来构建minibatches,如batch内正负样本比例为1:3,这个比例就像在采样中使用了alpha-balancing因子。而作者提出的focal loss则是在one-stage detection system中直接通过loss来解决该问题。
RetinaNet Detector

-
使用FPN作为网络骨干,用p3到p7层构建金字塔;
-
使用与FPN中RPN变体类似的translation-invariant anchor boxes;
-
Classification子网络是一个小的全卷积网络,与FPN每层相连接,且子网络的参数在整个金字塔内每层间共享;
-
Box regression部分使用的是class-agnostic bounding box regressor,和Classification两个网络共享一个网络结构,但是分别用不同的参数(以往的工作中一般是分类和回归完全共享同一个网络)。
Experiments


总结
-
针对单阶检测器的正负样本极度不均衡的问题(二阶检测器一般会通过选择处理第一阶段的proposal或并对第二阶段做有偏采样构建minibatch),提出一种动态缩放的交叉熵损失去替换标准的交叉熵损失,添加一个针对类别的系数,在正确类别的置信度提高同时,该类别的系数会慢慢衰减至0,以突出另一个类别的训练达到平衡样本的效果。
-
再添加一个针对样本的权重因子,样本越容易区分则因子越小,对损失大小起到调整作用,减少容易样本的贡献,专注于少量的困难样本。