
论文: Zhang S, Zhu X, Lei Z, et al. FaceBoxes: A CPU Real-time Face Detector with High Accuracy[J]. 2017.
Github: https://github.com/zeusees/FaceBoxes
论文算法概述
提出一种能在CPU上实时运行的人脸检测模型FaceBoxes。该论文主要有四点贡献:
1、设计出Rapidly Digested Convolutional Layers (RDCL),使检测在CPU上能达到实时;
2、引入Multiple Scale Convolutional Layers (MSCL),通过扩大感受野并将anchors分散到不同的层上去,用以处理不同尺度的人脸;
3、提出一种新的anchor稠密话策略,用以提高小人脸检测的召回率;
4、该模型在多个数据库上能取得较好效果。
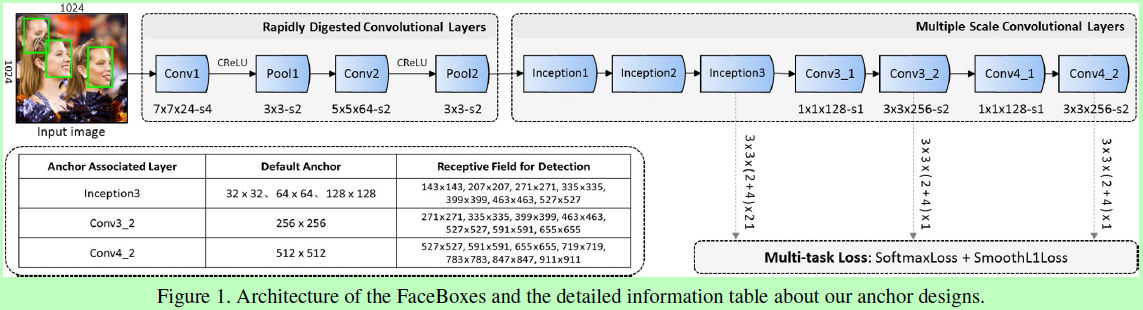
Rapidly Digested Convolutional Layers
-
将conv1、pool1、conv2和pool2的步长分别设为4、2、2、2,则共32倍缩小;
-
核大小要小以提高速度,但也要足够大以减缓维度降低造成的损失,则论文conv1、conv2和所有池化的核大小分别设为7x7、5x5、3x3。
-
使用CReLU减少计算量,参考论文《Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units》。
Multiple Scale Convolutional Layers
RPN一种类别不可知的物体检测算法,在Faster RCNN中用于region proposals的生成。但RPN若作为一个单独的检测器来使用,则无法达到较好的效果。
作者认为主要有两个原因:
-
在RPN中,anchors仅跟最后一层卷积层相关联,而该层网络的特征和分辨率都较弱,不足以处理各种尺度的人脸;
-
与anchor相关联的层负责检测对应尺度范围的人脸,但这里只有单一感受野而不能满足各种尺度。
作者的处理方式是:
-
将anchors与多个不同的层相关联,如图1中Inception3、conv3_2、conv4_2;
-
采用Inception模型,内含多个不同大小的卷积核,具有多种大小的感受野。
Anchor densification strategy
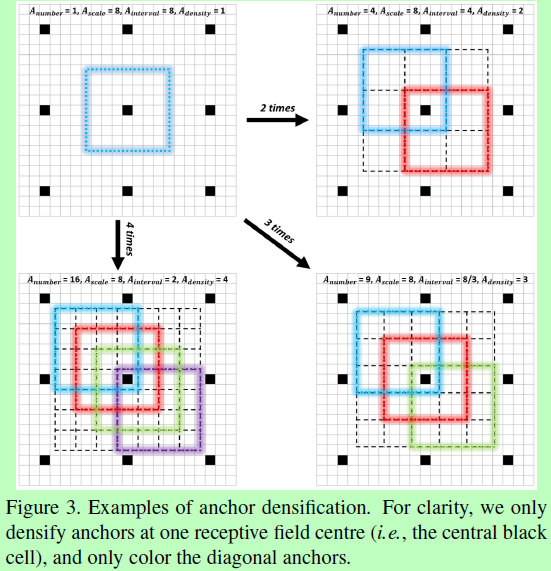
anchor设为1:1的正方形,其大小也如图1所示。默认Anchor的覆盖间隔与对应层的滑动步长一致,例如conv3_2的滑动步长是64,而其anchor为256x256,即在输入图像上每64个像素就套上一个256x256的anchor。定义anchor的覆盖密度为:A_density = A_scale / A_interval,A_scale是anchor的尺度,A_interval是覆盖间距。这里对应着Inception3、conv3_2和conv4_2的默认anchor的间距分别为32,32,32,64和128,那么对应的密度则为1,2,4,4和4。这就使每个尺度上的anchor密度不均衡,特别是小尺度对应的anchor过于稀疏,会导致对于小脸检测的召回率不高。所以作者提出一种新的anchor稠化策略,这里将32x32的anchor增加4倍,64x64的增加2倍,使达到均衡。如图3所示。
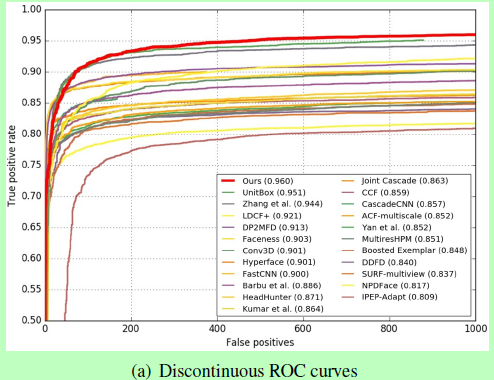
Experiments

总结
基于SSD优化:
-
使用了CReLU去减少计算量;
-
对RPN进行了调整,将anchor与多个层关联(即SSD的方式),并采用Inception结构以增加感受野种类,后直接输出最终的检测结果(原始的RPN只用于提取proposal,作者认为RPN中anchor只跟最后一层卷积相关联,特征图分辨率、特征表达能力和感受野都较为单一,若其结果直接作为最终结果则无法满足多尺度人脸的检测。)
-
因为结合了多层网络,每层尺度不同,则anchor的覆盖密度不同,则采用一种anchor稠化策略,调整anchor的步长来平衡每层的anchor,如这里将32x32的anchor增加4倍,64x64的增加2倍。