
论文: J Hosang, R Benenson, B Schiele .Learning non-maximum suppression.
论文算法概述
物体检测器的发展趋势是逐渐往端到端的方式走,即候选框获取、提取特征和分类器集成在一个网络上。而非极大值抑制NMS是其中最重要的部分,而标准的NMS是纯手工设计的,通过固定的距离阈值来简单地进行贪婪聚类,这里称为GreedyNMS.。
作者认为GreedyNMS有以下两个缺点:1)GreedyNMS为一般检测器的最后一个步骤,为单独的一个模块,阻碍的检测器的端到端训练。2)GreedyNMS通过固定的参数来决定抑制的范围有多大,以剔除多余的检测框,若抑制的范围太广容易去掉附近高分的检测框而造成误报;另一方面,如果物体相互很靠近,即附近的检测窗口可能是有效目标,则GreedyNMS很难提高检测器的召回率,参数较难调到合适通用。即如果图像目标很少,GreedyNMS的作用不大,如果图像目标很多,并挨在一起,GreedyNMS也无能为力。
针对这些问题,该论文中提出一个新的网络框架来实现NMS的效果,且仅需输入候选框的评分和位置,而不需要借助图像信息和其他算法。实验证明,该做法能提高物体定位精度并降低对遮挡的影响。

Doing NMS with a convnet
对于检测器,相似的输入就会有相似的输出。如果一个检测器对每个物体都只有一个检测框会达到高分,就需要对其他检测框进行限制,则多个检测框就需要联合处理,让检测器有能力去判断哪些是重复的检测框,这些检测框中应只有一个会达到高分。总之,该实现NMS的卷积网络需要达到两个必须的条件:1)由一个loss函数去惩罚重复的检测框,使检测器知道目标是对每个物体只留下一个准确的检测框;2)对临近的检测框进行联合处理,使检测器有这些必要的信息去知道该物体是否被多次检测。
这里的设计避免困难决策,并且不会去掉检测框去生成一个更小的检测框集。文中重新将NMS转换成一种再次评分的任务,去尝试降低已经被检测过的物体上的检测框的评分。通过再次评分后,一个简单的阈值就足以减少检测框的数量了。
Loss
如果一个检测器对每个物体只输出一个高分的检测框,那么这个检测器的损失函数必须要抑制对同一个物体的多个检测结果,无论这些检测框之间有多靠近。一个检测器的好坏由测试集的评估标准来决定,一般的测试基准中会把检测结果以置信度从上往下排序,取高分者。而被匹配过的物体不会再次被匹配,若直接将多余重叠的检测框视为负样本,会降低检测器的准确率。文中作者为此定义以下损失函数:

这里对每个检测框的损失都通过匹配过程中生成的yi与其他检测框相关联,权重w用来抵消检测任务中个别类别样本极度不均衡的影响。使用该损失函数后,该检测任务就变成了类似于多标签的形式,检测框与置信度和类别都有关。因为这里目的在于对检测框重新打分,所以允许一些检测框被屏蔽掉,而不改变他们的类别(以往的是非正则负)。这样,只需要将检测框匹配到物体的对应类别,而分类问题仍然是二分类的。在重新打分后,使用一个one-hot encoding:一个零向量,只包含该位置对应某类别的评分。而因为mAp的计算与类别大小无关,这里将权重引入,使类别的条件权重均匀分布。
“Chatty” windows
为了有效减小上面提到的loss,需要网络在输出检测结果的同时联合处理检测框。文中设计了带有重复结构的网络,这里称这种重复的结构为blocks,具体如图3所示。一个block能让每个检测框与其相邻框进行信息互联,随后更新自己检测框的特征表示。堆叠多个这样的block,则让网络在每个框的信息互联和更新框的特征表达之间不断交替,文中称之为GossipNet (Gnet)。
Detection features。网络的block的输入是每个检测框的特征向量,输出更新后的特征向量,如图2所示。多个block是重复迭代的,一个block的输出会是下一个block的一个输入。这里的特征向量都是128维的,最后一个block的输出会被用于对每个检测框生成新的评分。第一个block的输入为全0向量,未来优化中可考虑以图像特征代向量替这个全0向量。检测框的信息是以成对“pairwise computations”的方式输入到网络中的,如图3所示。
Pairwise detection context.每个mini-batch包含一张图片上的所有检测框n,每个框都表示为一个c(128)维的特征向量,因为需要信息互联,意味着需要在整个batch的数据中进行操作。作者使用了一个detection context layer,对与每个检测框di,生成所有的检测框对(di, dj),dj为与di有部分重叠的框(IOU>0.2)。一对检测框的特征表示包含有检测框本身的特征向量和g维的检测框对的特征,即共l = 2 x c + g维。如果检测框di有ki个临近检测框,则会生成一个大小为K x l的batch,其中K=(k1+1)+(k2+1)+…+(kn+1),其中“+1”表示包含自身的(di, di)的检测框对。在每个mini-batch中,每次检测得到的检测框对的数量都是不定的,为使其数量固定来获取固定大小的特征表示,该网络框架中对每次检测得到的所有检测框对使用了全局的极大值池化(K x l -> n x l),随后接着普通的全连接层来更新检测框的特征,如图3。
Detection pair features.每个检测框对的特征包含一下几个属性:(1)IoU;(2-3)x和y方向上的归一化距离,归一化的L2距离;(4-5)宽和高的尺度差异(e.g. log (wi / wj));(6)宽高比例差异log (ai / aj);(7-8)两个检测框的评分。将每个检测框的原始特征向量输入到三个全连接层中,去学习检测框对的特征,输入到每个block中。
Block.一个block迭代一次,让每个检测框与其各自的临近框信息互联,并更新自己的特征表示。Block中包含一个降维操作、一个基于检测框对上文信息的网络层,两个单独应用于每个检测框对的全连接层、池化层,以及又两个全连接层。后面的两个全连接层用于把之前的降维升回去。第一个block以0特征作为输入,最后的block输出到三个全连接层中单独为每个检测框预测新的分数。
Parameters.文中实验的网络有16个block,检测框的特征向量是128维,然后在构建检测框对的上下文信息之前降维到32维,最后一个block接着的全连接层将特征升回到128维。


Experiments
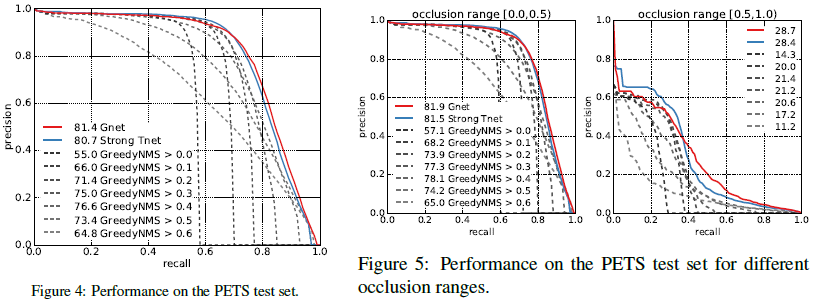
总结
普通NMS的缺点:1、作为一般检测器的最后一个步骤,为单独一个模块,阻碍了检测器测端到端训练;2、用于抑制的参数难调,无法以一种参数适用多种场景。
处理思路:1、由一个loss函数去惩罚重复的检测框,使检测器知道目标是对每个物体只留下一个准确的检测框;2、对临近的检测框进行联合处理,使检测器有这些必要的信息去知道该物体是否被多次检测。
具体做法:1、提出一个新的loss函数,对检测框重新打分,抑制对同一个物体的多个检测结果。每个检测框的损失都与其他框相关联,并涉及置信度和类别信息(联合评分,而不是以往的只取置信度),同时允许一些检测框被屏蔽掉而不改变它们的类别(以往的是非正即负);2、设置了一个detection context layer来对每个检测框将与之有一定重叠的所有检测框进行组对,两两一对,把每对输入到多个相同的block中,让每个检测框与其相邻框进行信息互联。因为每次得到的检测框对数量不定,所以使用全局极大值池化来固定特征图大小,随后以普通的全连接层来更新检测框的特征表示。