
论文: Yu J, Jiang Y, Wang Z, et al. UnitBox: An Advanced Object Detection Network[C]// ACM on Multimedia Conference. ACM, 2016:516-520.
论文算法概述
目前常用的物体检测方法采用CNN的方式,将物体边框的看成是四个独立的变量,使用L2 loss对其分别进行回归,但这四个变量实际上是相关的,会导致定位精度降低。为解决这个问题,提出一种新颖的Intersection over Union (IoU) loss用于边框预测,它将预测框的四个边界值作为一个整体进行回归。提出的网络在FDDB上达到了最优效果。
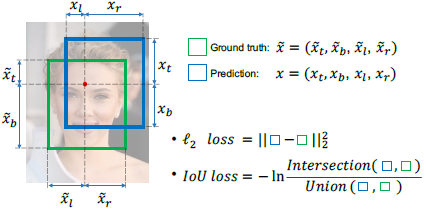
L2 Loss Layer
L为定位误差,L2 loss定义为: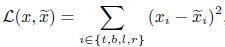 .
.
L2 loss用于边框回归主要有两个缺点。第一是将边框四个坐标点看成独立的变量进行回归,但实际上四个坐标点高度相关。第二是如公式所示,给定两个像素,一个在大的边界框内另一个在小的,那么前者在惩罚项上比后者会有更大的影响,因为L2损失是非归一化的,这种不平衡会导致网络更关注大的物体而忽略小的。为了解决这个问题,前面的论文中有提出在训练阶段将固定大小的图像块输入网络中,而在测试时使用图像金字塔,这样L2 Loss就被归一化了,但检测效率不高。
IoU Loss Layer: Forward
这里提出的IOU Loss可以解决以上L2 Loss的缺点,计算公式流程如下:

其中~x!=1,表示像素(i,j)落入了有效的物体框内,x(t,b,l,r)均为相对该像素点的距离,则X是预测框面积,~X为GT框面积,Ih和Iw是I的交叉区域的高和宽。IOU的取值范围在0到1,而L是以IOU为输入的必要的交叉熵损失,我们可以知道IoU是采样自伯努利分布(Bernoulli distribution的一种随机变量,p(IoU=1)=1,且交叉熵损失为 。与L2 Loss相比,IoU Loss将边框视为一个整体,因此预测结果会比L2 Loss的更精确;而且IoU Loss的定义自然地将IoU归一化到了[0,1]而不论方框的尺度大小,这样可以使网络进行多尺度训练单尺度测试。
。与L2 Loss相比,IoU Loss将边框视为一个整体,因此预测结果会比L2 Loss的更精确;而且IoU Loss的定义自然地将IoU归一化到了[0,1]而不论方框的尺度大小,这样可以使网络进行多尺度训练单尺度测试。
IoU Loss Layer: Backward
符号与Algorithm1中对应。

UNITBOX NETWORK
由VGG16修改得到,去掉了全连接层并添加了两个分支的全卷积层分别去预测边界框和类别得分,将置信度的分支拼接到VGG stage-4后面,而边界框的分支则插入到stage-5。在训练阶段,unitbox有三个相同尺度的输入,分别是:原图、表示一个像素是否落在目标区域的置信度的热力图、表示GT框内所有目标像素的边界框热力图。
为了预测置信度,在VGG stage-4后面添加了三个层:步长为1核大小为512x3x3x1的卷积层,用于将特征图做线性插值到原图大小的上采样层,用于将特征图与输入图像对齐crop层。而后则获得与输入图像大小一致的单通道特征图,在这基础上采用交叉熵损失(sigmoid cross-entropy loss)去回归生成的置信度热力图。在另一个分支,去预测边界框的热力图,使用相似的三个叠在一起的层在VGG stage-5后面,卷积和大小为512x3x3x4。并且插入一个ReLU层去确保边界框不会出现负数。预测框与IoU loss联合优化。最终的loss由两个分支的loss合起来各占一半。
测试时以人脸检测为例,首先在阈值化的热力图上使用椭圆去拟合人脸。而人脸的椭圆较粗糙不足以定位物体,则在这基础上选择这些人脸椭圆的中心点像素,根据这些被选择的像素提取出相应的边界框。

总结
认为L2 Loss用于边框回归的两个缺点:1、把边框4个坐标点看成独立的变量进行回归,但实际上四个坐标点是高度相关的。2、L2 Loss是非归一化的,所以对大框的惩罚会更大,会导致网络更关注大目标。
提出用IOU Loss去处理,公式是L=-ln(IoU)=-pln(IoU)-(1-p)(1-IoU),”IoU是采样自伯努利分布p(IoU=1)=1”。以IOU为目标,整个框视为一个整体,又将IOU归一化到[0,1],则与框大小无关,使网络可多尺度训练单尺度检测。