
论文: Qin H, Yan J, Li X, et al. Joint Training of Cascaded CNN for Face Detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:3456-3465.
论文算法概述
主要介绍了一种联合端到端训练级联CNN的方法,可结合MTCNN一起分析。联合训练框架如下图所示。在训练时,输入图像为48 x 48,输出为三个网络分支的联合loss。这三个分支的输入分别为12x12,24x24,48x48,使用来自非线性层的ReLU并在分类或回归层前面添加dropout层。

Training architecture
Branch x12:为全卷积神经网络,有两个滑动输出层。输入数据被缩小到12x12,输出前的最后的卷积层的大小为1x16x1x1。对于这两个输出层,一个输出概率分布(是人脸或不是),另一个则是输出边界框的回归偏移量。使用softmax loss作为分类loss和smooth L1 Loss作为边界框回归loss去联合优化该分支,定义如下:
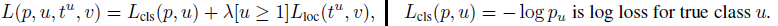
这里取入=1。对于回归,则如下:

这样就可以优化回归目标,将边界框在候选框(proposal box)的基础上去回归到GT box上。在训练时,回归的偏移量被归一化到0均值1方差。另外两个网络分支也一样。
Branch x12-x24:困难样本挖掘,将输入池化到24x24,输出为128维的全连接层,简称为24fc。24fc与x12中将1x16x1x1拉伸而成的1x16全连接层进行拼接,组成新的全连接层12-24fc。并为12fc的score threshold layer选择一个阈值,只有通过该阈值层的proposals才会贡献到最后一层的loss中。作者给的推荐阈值是0.1。x12-x24也同样输出分类loss和边界框回归loss。
Branch x12-x24-x48:更困难的样本挖掘,x12-x24-x48的输出为256维的全连接层,简称为48fc,将与12-24fc进行拼接,得到12-24-48fc。也为12-24fc选择一个阈值,仅让超过阈值的部分proposals通过,与分离的级联阈值类似,作者的推荐阈值为0.003。
Joint loss:每个分支都有一个是否为人脸的分类loss和一个边界框回归loss,分别赋予一个权重,相加起来作为最终的loss。
Implementation details
训练数据:为准备训练数据,先使用滑动窗口去遍历每张训练图像得到候选人脸图像区域。图像区域与任何一个GT框的IoU超过0.8的作为正样本。与每个GT框最大IoU在[0, 0.5)的作为负样本。样本都被裁剪后缩放到对应尺度输入网络中,使用左右翻转作数据扩增。最终正样本占整个训练集的比例为5%,
训练过程:每个训练样本都先以5为间隔被构建5层图像金字塔,则金字塔最小层为原图1/25大小。face proposals的准备采用步长为8的滑动窗口生成,基本如上训练数据准备一致。在训练阶段一中保持较小的正样本比例,这样可以减少false positives(实际为负预测为正),同时也加速了接下来的困难样本挖掘阶段。在作者实验中,设为5%的正样本是比较合适的。 x12分支的阈值设为0.1,x12-x24的阈值设为0.003,这两个阈值都是根据经验设定的。在一个合适的阈值范围内,训练过程会较为鲁棒。原则是保持召回率(少漏检)的同时,使阈值尽可能高,以便在前面层尽可能地过掉较多的proposals。
在训练的三个阶段中降低正样本的阈值,这样在后面的阶段中,我们可以使用困难样本去训练网络。
为了加快网络收敛,将三个网络分开进行训练,以训练的结果作为联合网络的初始值,再去训练联合网络。
Testing pipeline
测试流程部分包括三个分离的CNN。给定一个输入测试图像,全卷积网络输出一个特征图,该特征图上每个点为人脸置信度和边框回归值。这回归的目标是微调精炼边界框。每个点都与一个边界框相关联,对应该框的左上角点。在第一阶段后,留下评分超过阈值的部分框。通常采用NMS来去除高重叠的框,但NMS很耗时。所以作者提出了一种新方法来去重叠,受极大值池化启发,在输出特征图上采用与极大值池化类似的操作。与池化不一样的是,特征图的分辨率不改变,而如核大小选为k,则在k x k区域内,只有最高评分的点被保留,而其他的被置0。在stage-one网络中步长为2,所以当k=2时,结果相当于NMS的阈值设置为0.5。
留下来的边界框送入到第二阶段中,从原图中裁剪每个方框区域并缩放到24x24。对每个图像区域,网络都会输出一个评分及其边框回归结果。如在第一阶段中,排除掉了评分未超过阈值的边界框,并用回归来精炼边界框位置。在经过第二阶段后,一般只有几十个边界框被保留了下来进入第三阶段。操作类似,将区域裁剪出来并缩放到48x48作为输入,并对经过阈值过滤后的边界框进行回归精炼作为第三阶段的输出。最后,使用NMS对所有留下的边界框去重叠,得到最终的结果。在实际操作中,测试图像会先构建出一个图像金字塔去处理不同的人脸尺度。
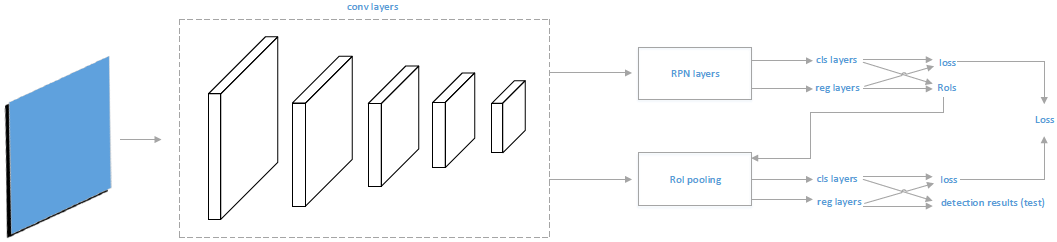
Joint Training of RPN and Fast R-CNN
为将Faster RCNN进行端到端训练提供思路,训练过程包含两步(原始的是四步),框架如下图所示。首先先单独训练RPN,但后用RPN模型去微调联合网络。用于faster RCNN的候选框由RPN在训练样本中进行测试时得到。在训练联合网络时,输入包括原始的RPN输入和由RPN模型得到的候选框,RPN得到的候选框作为联合网络中fast RCNN的RoIs。
Results
在小一点的数据集上联合训练的模型,在FDDB上结果为88.2% (1000 false positives),而分离训练的则为87.2。扩大样本后在FDDB上结果为90.8% (1000 false positives),在AFW上为98.73%。且顺便提出的RPN + fast RCNN联合训练在AFW上AP达到98.7%,而原始四阶段训练的则为97.0%,在FDDB上的召回率(1000 false positives)为91.2%和 98.7%
总结
级联三个网络用于人脸检测。
-
输入分别是x12、x24和x48,以48x48为原始图像大小,x12和x24由缩小得到。
-
训练时,为加快收敛,三个网络先单独训练,后再联合加三个网络的loss做加权和进行训练。
-
训练样本用滑动窗口来生成,窗口与GT的IOU达0.8则标为正样本,0到0.5的为负样本。且每个训练样本都以5为间距先做成5层金字塔再输入(测试时的输入图像也做金字塔)。
-
第二级和第三级网络的训练样本都会先基于前一级网络进行难例挖掘。
-
其中x12输入的网络是FCN(将人脸和非人脸的训练样本缩放到12x12输入,测试时输入全图则相当于以滑动窗口的方式截取12x12的图像块输入网络),输出前的最后的卷积特征图为1x16x1x1(后接分类和回归两个输出层,其中分类输出结点为2,而回归的是8),展开后会跟第二级和第三级网络的FC层合并。
-
测试时三个网络级联进行,第一级网络为了加速NMS,使用类似于极大值池化的方式来代替,即以窗口在特征图上以一定步长滑动,只取窗口内最高评分的点。得到的框依次进入二、三级网络,最后用NMS去重。