
论文:Hu P, Ramanan D. Finding Tiny Faces[J]. 2016.
Github:https://github.com/peiyunh/tiny
论文算法概述
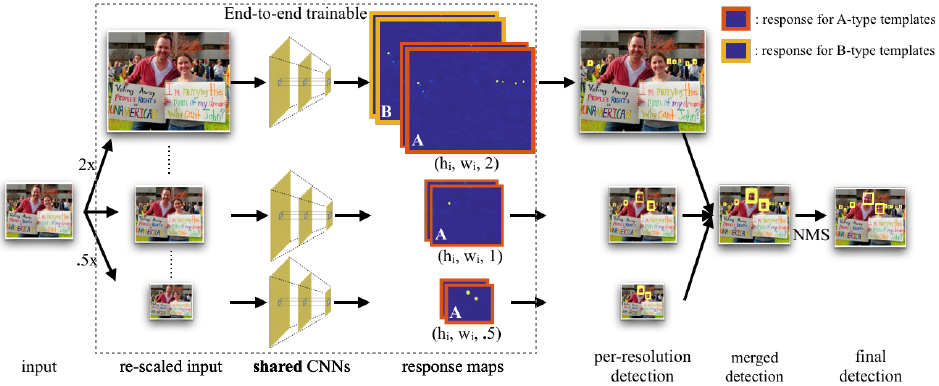
对于检测小的人脸主要有三个问题:尺度不变性、图像分辨率和上下文关系。文中提出对不同的尺度训练不同的检测器,为了提高效率采用多任务的模式,在单个网络中从多个层上进行特征提取(称为hypercolumn特征)。整体检测框架如下,先将输入图像构建一个粗糙的图像金字塔,将金字塔中每个尺度输入到网络中提取hypercolumn特征,由hypercolumn特征图得到相应模板的预测响应图,包括检测和回归。在给定的预测响应图中,从每个尺度上提取出检测框,然后合并到原始的尺度上,使用NMS得到最终的结果。文中A-type模板用于在金字塔所有尺度中检测40-140像素高的人脸,B-type用于在2x采样层中检测小于20像素的人脸。
Multi-task modeling of scales
传统的方法是训练一个单尺度的模板应用到密集离散的图像金字塔中(a),为了利用在不同分辨率上的信息,需要应对不同尺度的物体建立不同的检测器(b)。但这种方法在一些在训练集或预训练集上很少出现的极端的尺度上会失效。文中利用粗糙的图像金字塔去应对极端的尺度(c)。最后,为了提高检测小脸的性能,文中对额外的上下文信息进行建模,上下文信息在特定接受域在特定模板上实现效率高(d)。文中从深度网络内多个网络层中进行特征提取,在提取结果上设定模板(e)。

Human on context
在图左边有一个大脸和小脸,各有两张图,一张包含上下文,另一张没有。上下文信息对于人识别大的脸来说是不需要的,但如果脸非常小,则在没有上下文信息的时候是无法识别的。论文作者做过实验,对于很小的人脸图,在加上上下文信息后,误识率降低20%,而对于大的人脸,在加上上下文信息后,误识率降低2%。同时如直方图所示,当尺度很小时,按比例的大小的上下文起到的作用不大。文中把目标放在中心( foveal templates),扩展到约300 x 300的大小,如黄框所示。

How best to encode context
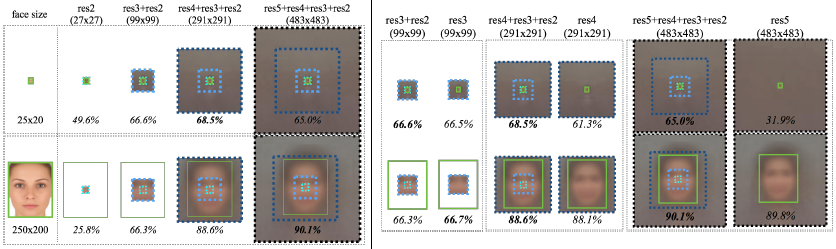
有趣的是更小的接受域对于小的人脸更有效,因为整个人脸是可见的。图中绿色表示实际的人脸大小,而虚线框表示各网络层上特征对应的接受域。Foveal descriptor对于小物体的准确检测很重要,小的模板(右图上)在只有res4情况下效果下降7%,在只有res5的情况下效果下降33%。与之相反,去掉foveal结构后并没有影响到大模板的效果(右图下),表明来自较低网络层的高分辨率对于小物体检测很有用。
How to generalize pre-trained networks
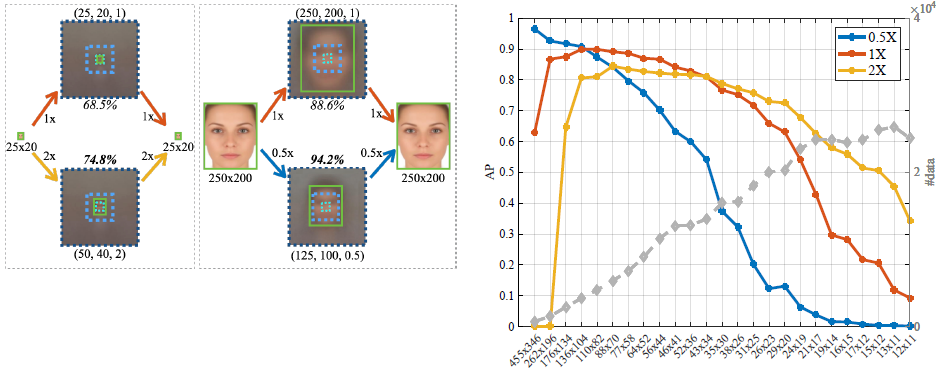
在检测25 x 20大小的人脸时,把为50 x 40大小人脸而微调的模型模板比微调置25 x 20的效果好。而在检测250 x 200大小的人脸时,把为125 x 100大小人脸为微调的模型模板比为250 x 200为微调的模型模板效果要好。这是为什么呢?假定预训练模型有适应过极端的适度,ImageNet里有超过80%的数据像素在40-140之间,考虑在归一化的情况下所有的图像都是224 x 224的,那么预训练模型很可能对在那些尺度范围内的物体检测做过优化。
这里粗暴地列举出一些尺度,粗糙地覆盖尺度空间,然后尝试对每个尺度采用三个不同的策略(缩小到0.5x,保持原来的1x,插值放大到2x)。如图所示,对于大的人脸(高大于140像素),使用0.5x的分辨率训练模型模板;对于小人脸(高小于40像素),使用2x的分辨率。在这大小之间,使用原来的分辨率1x。
总结
一般对应多尺度人脸检测的做法是:1、单尺度的模板应用到密集离散的图像金字塔中;2、应对不同尺度的物体建立不同的检测器(模板)。而文中将这两种方法结合,即多尺度输入多检测模板,而实验中的多模板包含有1x分辨率和2x分辨率的模板,其中2x分辨率是考虑到上下文信息对小人脸的作用(感受野包含小目标外一定区域时有助于判断目标是否人脸,将标签框扩大)。
具体流程是:先将输入图像构建一个粗糙的图像金字塔(.5x、1x和2x),将金字塔中每个尺度输入到网络中提取特征,由特征图得到相应模板的预测响应图,包括检测和回归。在给定的预测响应图中,从每个尺度上提取出检测框,然后合并到原始的尺度上,使用NMS得到最终的结果。