
论文:Opitz M, Waltner G, Poier G, et al. Grid Loss: Detecting Occluded Faces[M]// Computer Vision – ECCV 2016. Springer International Publishing, 2016.
论文算法概述
在标准的CNN检测器中,损失函数是基于整个图片进行信息计算的,则会导致学习出的网络会趋向于利用全局信息进行分类,所以在检测目标部分遮挡的情况下,容易造成误判和漏检。文中针对这个问题提出了Grid Loss,将CNN网络中最后的卷积特征图分割成多个子块,分别各自独立地最小化各个块的loss。强化了网络每个子块的单独的判别能力,使学习得到的特征对遮挡更具鲁棒性,并带有一定的正则化效果,提升了对遮挡人脸的检测性能。

Grid Loss Layer
GridLoss中每一个block的loss都是一个hinge loss:L=max(0,1 - t x y),则其定义如下所示。其中N为block(grid)的数量,m为界限(常数,文中实验设定为1/N,使每个block都有相同的贡献),y是{-1,1}为类别标签,wi和bi是对于block i的权重和偏置,令全局分类器的权重向量由局部分类器权重拼接而成w=[w1,w2,w3,,,wN],全局分类器的偏置则为局部分类器偏置的累加b=b1+b2+…+bN。公式的前半段为整个特征图的loss,后半段为各个block的loss,则中间加个入进行比重的权衡(文中实验设为1),使用SGD作为loss的优化函数。因为权重w是全局分类器和局部分类器之间共享的,而b为已经存在的参数bn的总和。所以与传统的分类层相比,这里只添加了N-1个参数,并且在检测时不会有额外的时间代价。
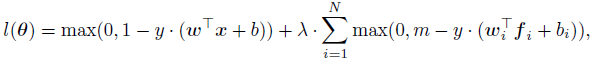
在训练的时候,整体的loss将样本的分类错误反向传播到隐藏层,同时某些blocks将给定样本错分类时,这些blocks对应的loss也会作为额外的信号反向传播。而对于足够判别能力的部件检测器将物体分类正确,则不会有额外的loss信号传回。这样在训练时,具有较少区别部分的误差信息会得到加强,使CNN更专注于加强弱的部分而不是具有足够区分度的部分。例如一个样本被整体检测器正确分类,但被部分部件检测器误分时,只有这部分的部件检测器的误差信号会被反向传播,使这些部件检测器区分能力更强。这样,一些具有较强区分度的部件影响将会较少,使各部件激活模式更加统一,在部分遮挡情况,检测器能够对其进行恢复。而在以往,这些被遮挡的部分可能对应着具有较大区分度的部分,剩下的未被遮挡的部件区分能力不够会导致检测失败。
好的特征具有高度区分性和去相关性,因此它们组合在一起时对于检测器来说是足够的。而gridloss的另一个优点是相对与标准的loss来说,它能够减小特征图的相关性。对于整体CNN检测器可能会依赖于少数中间特征去分类,而在gridloss下,CNN需要去学习中间特征使脸部的每一部分与背景相区分,得到一组各种各样的中间特征,特征多样性越大,则去相关程度就越大。对于gridloss的另一种解释是,使得到的分类器是综合了多个共享特征的部件检测器得到的,能够避免过拟合。
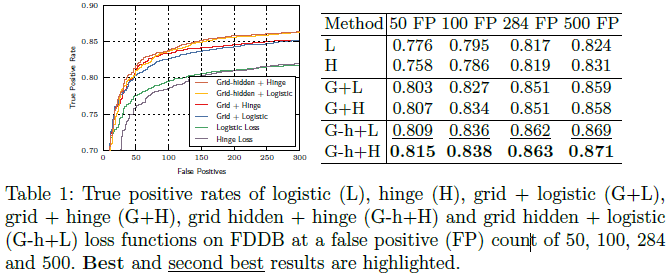
实验结果
总结
一般CNN检测器中,损失函数是基于整个图片进行信息计算的,则会导致学习出的网络会趋向于利用全局信息进行分类,所以在检测目标部分遮挡的情况下,容易造成误判和漏检。这里的gridloss是将最后的卷积特征图切分成多个块,每个块单独计算与最小化loss,以强化每个子快的单独判别能力。采用的loss是hinge loss,整体的损失为全局损失和各块的损失的加权和。
PS:
Softmax输出的是分类的概率,使所有输出相加为1,如对二分类的fc层会有两个输出结点,相加为1。而这里对每个块只有一个输出,只对自己负责与别的块无关,所以采用hinge loss,以小于的目标1的距离作为损失。