论文:Cai Z, Fan Q, Feris R S, et al. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection[J]. 2016.
Github: https://github.com/zhaoweicai/mscnn
论文算法概述
multi-scale CNN(MSCNN)用于目标检测,包含proposal子网络和检测子网络,都是端到端训练并且计算共享,使用多任务loss进行优化。在proposal子网络上,检测器应用于多个输出层,每个输出层应对物体某一尺度范围,所以接受域也对应着物体的多个尺度。直观地看,较低层的conv3具有更小的接受域,能更好地适应小物体。而更高的层如conv5则更适合大物体,则相当于用足够多个对应尺度范围的检测器来组合成一个强的多尺度检测器。在特征上采用反卷积操作做上采样,相比于在输入时做上采样,可以减少内存和计算消耗。
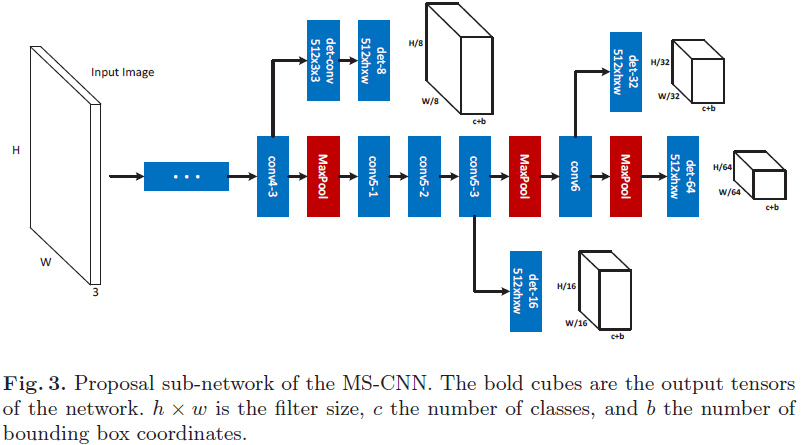
Multi-scale Object Proposal Network
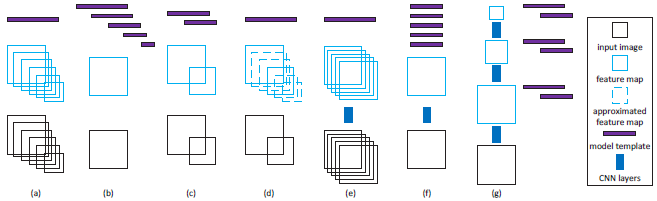
检测器本质上是匹配模板和图像区域进行点积,模板在空间上需要与物体相对应,常用的主要有两种策略去达到这个条件。第一个是训练单独的分类器模板然后对图像进行多次缩放,如图(a)所示,这种策略能够产生最精确的检测结果,但需要在不同尺度的图像上都做特征计算。另外一种策略是对单一尺度的图像采用多个检测器模板,如图(b),这种策略避免了多次计算特征图,但需要一个独立的包含每个尺度模板的检测器,较难得到较好的检测器。也有其他一些两者之间权衡的方法,如图(c),缩放少量的尺度和训练少量的模型模板;如图(d),对输入图像进行少量缩放,在两次缩放之间进行插值以填充没有缩放到的尺度;如图(e),将候选框图像块映射到CNN的一个尺度上,与图(a)有点相似,但特征的重复计算只对应着图像块,而不是全图;如图(f),RPN的多尺度机制,与图(b)有点相似,然而同一大小的多个模板集被应用到所有特征图,会导致有一些尺度与模板不一致,如单一尺度的特征图在感受野为228 x 228的CNN上会无法检测到小的目标(如32 x 32)和大的目标(如640 x 640);文中提出的方法如图(g),可以看成是图(c)的深度网络实现的扩展,但只使用了单尺度输入,与(e)和(f)不同,它利用了特征图的多个分辨率去检测不同尺度的物体,包含有不同大小的感受野,可以涵盖更大范围的物体尺度。
该检测框架如图3,包含多个检测分支,每个分支可以看成是对最终proposal的检测,这些分支都包含有一个单独的检测层。注意到在“conv4-3”的分支上接有一个缓冲卷积层,因为这个分支接近主干网络的较低层,更容易影响梯度导致训练不稳定,这个缓冲卷积层能够防止由该分支产生的梯度直接被反向传播到主干。
实现细节
数据扩增:一些论文中讨论过没有必要进行多尺度训练,因为深度网络擅长于学习尺度不变性。然而对于尺度范围非常大的数据库,如Caltech和KITTI等,进行多尺度训练是有必要的。文中对原图进行随机缩放到多个尺度中进行扩增。
微调:训练fast rcnn和RPN需要大量的显存和小的mini-batch,因为输入图像很大,这样会导致训练过程较艰难。事实上,许多背景区域对训练影响不大但却占用大部分的内存。因此论文中从原图中随机裁剪出包含物体图像块(448 x 448),这样能很大程度上减少内存使用。因为booststrapping和multi-task loss在刚开始训练的迭代中不稳定,这里采用两个阶段的训练过程。第一阶段使用随机采样和小的平衡系数(分类与回归的平衡系数)入(如0.05),用0.00005的学习率迭代10000次。得到的模型作为第二阶段训练的初始值,这时采样使用booststrapping,系数入=1,设置“det-8”的alphai=0.9,其他层的alpha为0.1。
Object Detection Network
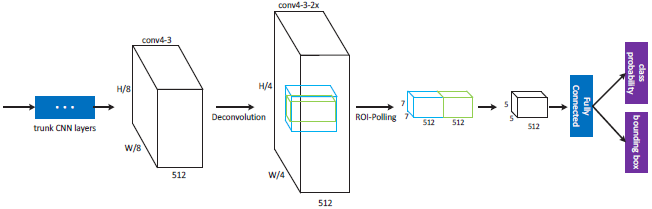
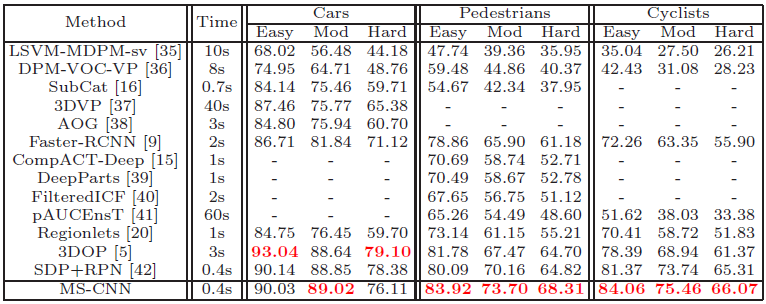
实现结果
总结
分proposal网络和检测网络,两个网络共享主干。创新点在proposal网络上,取多个不同深度的层,使用FCN来提取候选框,全卷积最后输出维度为类别数加坐标值个数,即c+4。前面两通道属于对每个特征值做多分类(每个特征值对应原图的一个图像块,与YOLO相似),后面四个通道则结合每个特征值分类结果做边框回归。得到候选框后通过ROI池化进入普通的检测网络做检测。