代码:https://github.com/daijifeng001/caffe-rfcn; https://github.com/daijifeng001/r-fcn ; https://github.com/Orpine/py-R-FCN
博客推荐:http://blog.csdn.net/zb1165048017/article/details/52767478; http://blog.csdn.net/bea_tree/article/details/51817263; http://blog.csdn.net/u010678153/article/details/52639136
论文:Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks[J]. 2016.
论文算法概述
提出一种基于区域的全卷积神经网络 Region-based Fully Convolutional Network (R-FCN)用于物体检测,与其他基于区域的检测器如Fast/Faster R-CNN在每个子区域网络多次计算相比,文中采用的全卷积网络可以几乎共享整张图像的所有计算量,使用一个对位置敏感的评分映射图来解决图像分类和物体检测平移不变形的难题。R-FCN可以将如ResNet等全卷积的图像分类器作为主要组件转换为目标检测使用。速度是faster rcnn的2.5 - 20倍。
现在普遍的目标检测深度网络可以从ROI池化层分成两个子网络,一是共享计算的全卷积网络,另外是ROI后面不共享计算的网络。而resnet和googlenet都是全卷积网络,所以可以用于作为物体检测中共享计算的全卷积子网络部分,但考虑到定位精度问题,Faster R-CNN中的ROI池化层被添加到卷积层和ROI后的网络之间。虽然精度提高了,但运算速度下降了,因为每个ROI的计算不共享。
图像分类任务希望translation invariance,物体无论怎么变化都可以被识别,而深度卷积网络可以很好的做到这点;而物体检测任务有位置信息,需要translation invariant,如物体的变动需要候选框也有对应合理的变化。则用分类网络来构成检测器需要解决这个矛盾,所以添加ROI池化层到卷积网络中,基于区域的操作分解了平移不变性,当评估预测不同的区域时post-RoI卷积层也不再具有平移不变性。然而这种设计牺牲了训练和测试的效率。
文中提出的网络包含共享的全卷积的框架与FCN一样,为了将平移可变性包含到FCN中,使用一堆特定的卷积层作为FCN的输出来构建了一组对位置敏感的评分映射图,每个评分映射图包含着位置信息。在FCN的顶部,添加对位置敏感的ROI池化层来获取评分特征图的信息而不带权重信息。整个框架的训练都是端到端的,每个可训练的层都是卷积的并且在整张图像上共享计算,也涵盖了用于物体检测的空间信息。


具体方法
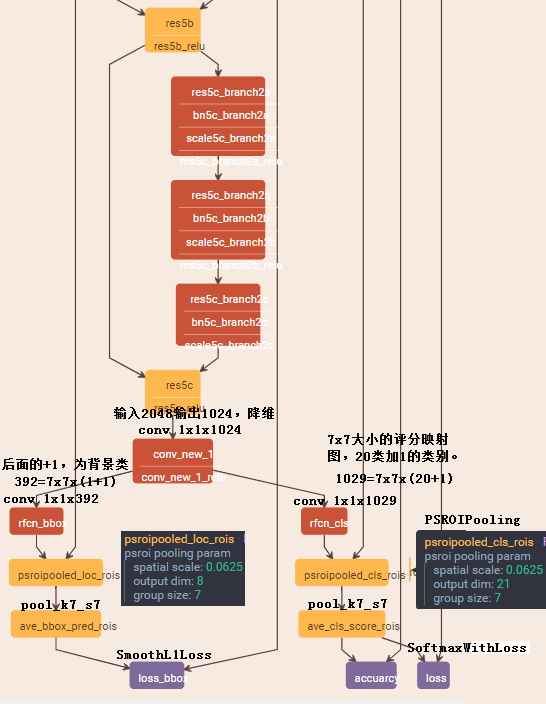
与RCNN相似,包含region proposal和 region classification两步,其中候选框的提取采用RPN(faster rcnn中提出,其本身就是全卷积网络),将RPN和R-FCN之间的特征共享(与faster rcnn中类似)。 给出ROIs后R-FCN框架被设计用于将这些ROI进行分类。在R-FCN中,所有可学习的权重层都是卷积的并且用于整张图像的计算。最后的卷积层中每个类别都得到K^2个位置敏感的评分映射图(position-sensitive score maps),所以对于C类物体加一类背景有k^2 x (C+1)个通道数的输出。这k^2个评分映射图与具有相对位置信息的k x k的空间网格相关联。如k x k=3 x 3,即有9个映射图(上左,上中,上右,中左…右下)包含有物体类别信息。R-FCN以位置敏感的ROI池化层(position-sensitive RoI layer)结尾,这一层聚集了最后的卷积层的输出并为每个ROI得到对应评分。
文中网络的骨架采用ResNet101,并去掉global average和fc分类层,而resnet101的最后一层卷积层是2048维的,所以添加一个1024维的1x1卷积层来降低维度,然后加了k^2(C+1)通道的卷积层来产生评分映射图。即最后的卷积层对每一个类别都产生k^2个评分映射图(图中每个颜色块都含有每一类别对应的评分映射图),对于w x h的ROI,池化得到的bin的大小为(w/k x h/k)。对于第(i,j)个池化单元里数值信息都只对应着第(i,j)映射图:

然后通过简单的求均值进行投票,使用softmax完成分类:
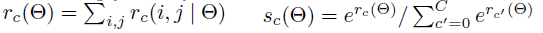
而在之前得到k^2(C+1)通道的特征图的同时,添加1个4k^2维的卷积层用于边界框回归,每个ROI生成的4k^2维向量取平均投票后得到4维的坐标向量。 其中训练为单尺度,均缩放到600个像素,整体损失为分类的交叉熵损失与回归损失(smooth L1 loss)之和。过程中采用online hard example mining (OHEM),即假设每张图片得到N个候选区域(来自RPN),在前向运算中评估这些候选框的loss,并进行排序,选取loss最高的B个ROI进行反向传播学习(其他不管)。
可视化
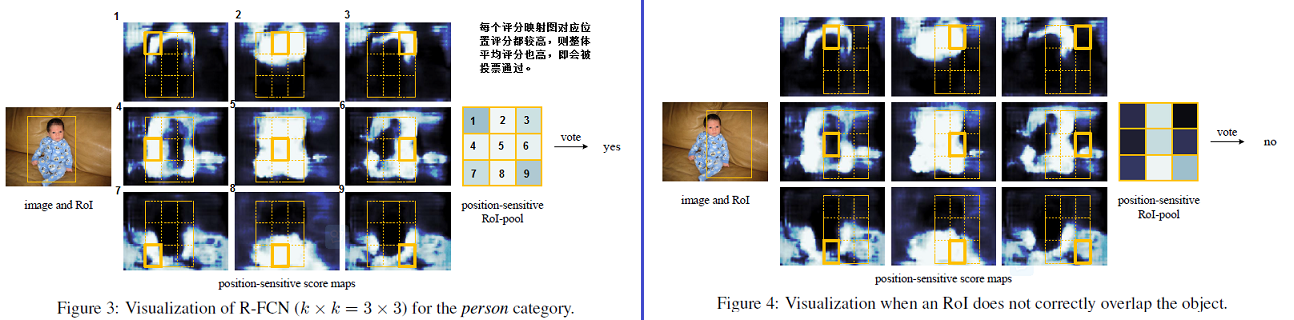
图中可视化了由R-FCN学习得到的k x k=3 x 3的position-sensitive score maps位置敏感的评分映射图。如图3中,候选框成功框选目标时,该ROI产生的k x k=9个评分映射图,池化后每个映射图得到一个池化bin,即会有3 x 3个bin,若每个bin的分数都较高则投票(取均值)后分数也较高,则认为是目标。反之,平均分数不高,则为非目标。
试验与结果
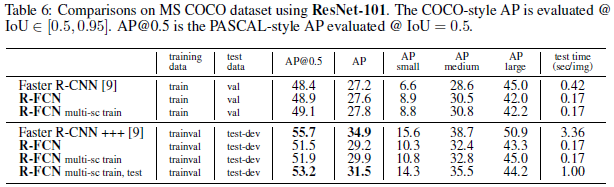
R-FCN采用的训练集是VOC07+VOC12+COCO,在数据集 VOC 07 和 12 上的 mAP 分别为 83.6% 和 82%,在Nvidia K40 GPU中测试每张图像耗时170ms。
总结
主要是为了处理ROI池化加全连接使位置信息丢失的问题,提出了对位置敏感的PSROIPooling。先设对位置敏感的评分映射图大小为k,类别数为C,则对特征图接上1x1且通道数为kxkx(C+1)的卷积层去重新排布特征图,截出每个ROI特征图块(ROI由RPN提取),各自输入到PSROIPooling中,PSROIPooling即相当于分组的ROI池化,该池化层将特征图分成kxk组,每C+1通道的特征图为一组单独进行ROI池化到固定尺度,论文直接就设成全局池化,输出为1x1x(C+1)。则共有kxk组ROI池化输出,然后将不同的组的输出特征图排布在一起组成一个kxkx(C+1)的新特征图。这样会使上面用于重排特征图用的1x1的kxkx(C+1)个卷积核中,每C+1个卷积核就对应着特征图的一个空间位置(而不是原来的每个卷积核对应一个通道的全部空间),即带有了位置信息,训练后得到的特征图会对位置敏感。
最后对这kxk的特征图进行投票,以全局均值池化实现(即kxk大小的均值池化,即相加求平均),最后得到的是1x1x(C+1)的特征向量,每个元素对应一个类别的评分。假设整个ROI区域都在目标内,则PSROIPooling特征图的kxk个位置激活程度都很高,那么全局均值池化输出也会很大,假设ROI只有一半在目标内,则kxk特征图中会有一半激活程度高,另一半低,则全局均值池化输出也相对稍低一些。