
论文:Ranjan R, Patel V M, Chellappa R. HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition[J]. 2016.
论文算法概述
提出使用卷积神经网络同时实现人脸检测、关键点定位、姿态估计和性别识别。浅层特征能包含更好的边缘角点等局部化信息,适合用于特征点定位和姿态估计。而高层特征则适合于物体分类检测等更复杂的任务。因此可以将卷积网络的中间层特征利用起来应对多个任务。而卷积网络中包含多个网络层和很多特征图,信息量大,无法直接有效地应用于多任务中,因此需要一个特征融合的方法,将特征转换到公共子空间中,便于进行线性或非线性融合。文中构建一个单独的fusion-CNN去完成中间特征的融合,而深度网络和fusion网络可以同时进行端到端训练,采用多个loss完成对多个任务的训练监督。
论文贡献:
-
提出一种CNN框架,通过融合中间层特征实现人脸检测,关键点定位,姿态估计和性别识别;
-
提出两种后处理方法:迭代区域选择和基于关键点的NMS;
-
对比了针对单任务的RCNN和使用文中的中间层特征融合的方式实现多任务RCNN的性能比较;
HyperFace
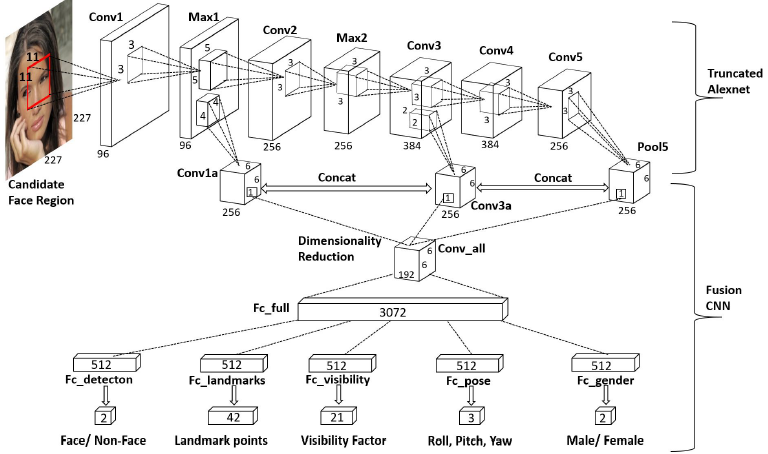
三个模块,第一个模块使用selective search从图像中得到候选区域,并缩放到227 x 227输入到网络中;第二个模块是将缩放后的候选区域输入到CNN中判断是否为人脸,如果是人脸,则网络继续提供人脸特征点定位、姿态估计和性别识别;第三个模块是后处理部分,包括候选区域迭代和NMS。
文中网络设计基于Alexnet,使用一个的网络将max1,conv3和pool5层特征融合。但这些层的特征维度不一致不能直接concate,所以文中在max1和conv3后添加了conva和conv3a来获取维度一致的特征图,然后将其与pool5进行拼接,而拼接后维度较高,使用1 x 1的卷积层去降维(googlenet的做法),再通过一个大的全连接层,后由多个独立的小全连接层分别应对各个任务。
-
人脸检测:采用selective search获取候选区域,与标签重叠超过0.5的当作正样本,小于0.35的为负样本,使用softmaxloss进行训练;
-
关键点定位:使用aflw(有部分点误标,有部分点不可见而未标),重叠大于0.35的当作正样本,坐标点被归一化后输入训练,采用EuclideanLoss;
-
关键点可见性预测:用于预测某关键点是否可见,重叠达0.35为正样本,采用EuclideanLoss;
-
姿态估计:估计roll,pitch,yaw,,重叠达0.5为正样本,采用EuclideanLoss;
-
性别识别:二分类,重叠达0.5为正样本,采用softmaxloss;
整体的loss为5个loss的加权和: aD = 1; aL = 5; aV = 0.5; aP = 5; aG = 2;
Iterative Region Proposals (IRP)
利用每次的关键点定位得到一个新的候选框,输入到网络中得到一个置信度更高的框和更准的关键点,不断迭代;

Landmarks-based Non-Maximum Suppression (LNMS)

总结
三个模块:
- 第一个模块使用selective search从图像中得到候选区域,并缩放到227x227输入到网络中;
- 第二个模块是将缩放后的候选区域输入到CNN,并取了三个不同层级的特征图以降维和升维的方式concat在一起,再接1x1卷积降维,后接大的全连接层,再对各任务接小全连接层,做是否人脸、人脸特征点定位、姿态估计和性别识别的任务;
- 第三个模块是后处理部分,包括候选区域迭代(用每次的关键点预估一个新的框,然后再送入网络,算一个置信度更高的框和更准的关键点)和LNMS(Landmarks-based Non-Maximum Suppression)。