
论文:Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. Computer Science, 2015.
代码:http://pjreddie.com/darknet/yolo/
推荐博客:https://blog.csdn.net/hrsstudy/article/details/70305791
论文算法概述
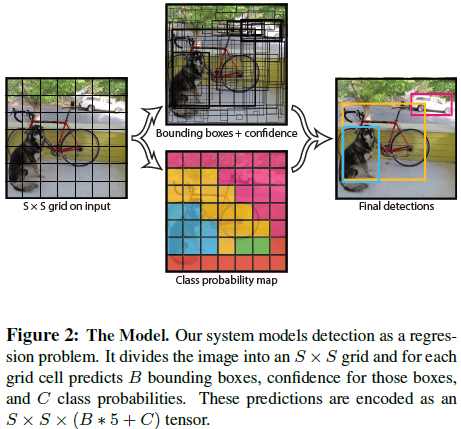
YOLO,将物体检测的多个组建融合到单一的卷积网络中,输入全图可以同时预测多个包围框及其属各类别的概率。可以进行端到端训练并保持较高的平均准确率实时检测。系统中将输入图像分割成S x S个单元格,当物体落入到某单元格中,则该单元格则负责检测该物体。每个单元格要预测B个候选框及其是否含有目标的置信度。每个候选框有(x,y,w,h,confidence)五个参数,(x,y)为相对于该单元格的偏移,而confidence表示预测框和任意ground truth box的IOU。流程大致为:将图像缩放到固定大小(448 x 448),用网格进行分割,每个网格预测B个候选框,各得到5个参数,用阈值和NMS(Non-maximum suppression)去掉部分候选框即可。
网络输出为S x S x (B x 5 + C),以下网络结构输出为例,PASCAL VOC 的20类,则C = 20,网格分为7x7,B为2(每格可以有两个框),5为五个参数,得到每个单元格对应2x5+20=30维的张量,含有两个候选框及其位置,加上每一类的概率,因为限定了每单元格只能识别一类,所以20不用x2。

优点
-
检测速度快,把检测看成是回归问题,不需要复杂的过程。速度快,比其他实时检测算法的平均准确率高;
-
YOLO在训练和预测时都对全图进行分析,可以对全图的上下文信息等进行提取。Fast-RCNN把部分背景图像块识别成物体(作为候选框)的原因主要是它无法分析到更大一些的上下文信息,所以YOLO错误候选框会比Fast-RCNN少很多。
缺点
-
检测精度不是很高,只是说比其他能实时检测的算法高;
-
具有空间约束,每个单元格只能预测两个框和一个类别,即成群出现的小物体(多物体在同一单元格)无法识别。
-
无法适应于有不寻常长宽比的物体或其他情况,泛化能力较弱。
-
由于算法的损失函数问题,对大小物体的检测误差一样对待,而因为在大物体上的小误差影响不大,小物体上的小误差会造成很大影响,因此该算法对大小物体上的检测还需要提高。
-
因为有全连接层,且没有使用SPP等相应措施,所以输入图像需要缩放到固定大小。
总结
以分栅格的方式直接对全图进行检测。论文中,在VOC PASCAL上训练,设S=7,即将全图分成7x7的栅格,共49个格子,每个格预测2个方框(每个方框有x、y、w、h和confidence共5个预测值),且VOC PASCAL上类别C=20,即一格对应的输出向量长度为2x5+20=30,所以最终得到的特征图维度是7x7x30。
PS:
- 论文中设成7x7栅格,每格有30维度的特征,前10维是两个框的预测结果,但计算loss时只选其中一个参与,以与GT的IOU最大者来负责该格子的回归及是否有目标的loss的计算。而分类loss固定由后20维特征参与。
- 最后每个格子有自己的预测结果,多个格子合在一起可判断出物体所占面积和大致形状。如1、2、3号格子都是预测得到狗的类别,那么覆盖1、2、3格子的地方应有“狗”,呈长方形。