
论文:Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J]. Computer Science, 2015.
代码:https://github.com/weiliu89/caffe/tree/ssd
推荐博客:http://www.sohu.com/a/168738025_717210
推荐博客:http://www.360doc.com/content/17/0810/10/10408243_678091430.shtml
论文算法概述
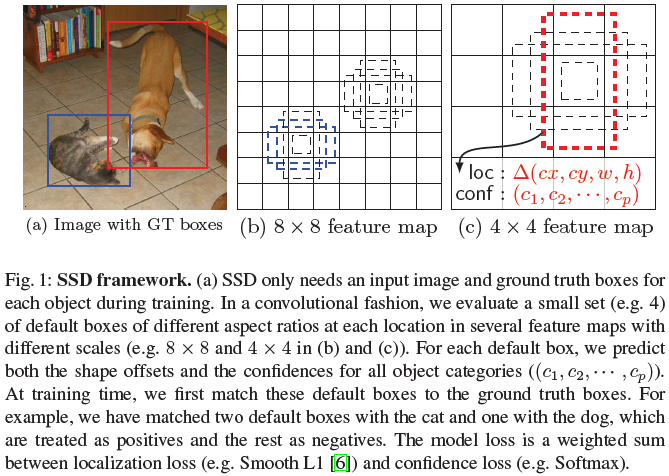
SSD(Single Shot MultiBox Detector),单一的深度神经网络用于检测多个类别的物体,可进行端到端的训练,速度比之前的single shot detectors(YOLO)快,准确率与Faster-RCNN相当,甚至对于低分辨率的图像也能取得不差的效果。而其核心在于使用应用于特征图上的小卷积滤波器进行物体类别与区域预测,如图1某层8 x 8大小的特征图,使用3 x 3的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息。为了实现高检测率,在不同尺度的特征图上进行多尺度的预测,并根据长宽比来分离预测结果。
模型
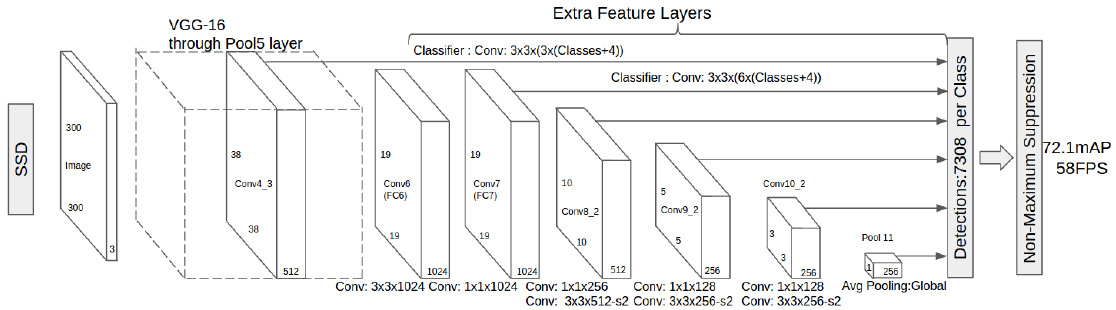
以较好的物体分类网络(如VGG16)中分类层前面的网络作为基础网络(truncated base network),再添加上一些网络结构来实现物体检测,该模型有以下几个特点:
-
采用多尺度特征图,添加多卷积层到基础网络后面,逐层将尺寸减小使可以用于多尺度检测;
-
添加的每个卷积层都可以使用一系列卷积滤波器产生一个检测结果,如下结构图(classifier对应)所示。对于m x n的p通道特征图,一个可能的检测结果的参数的基本元素是3 x 3 x p的小卷积核,生成每类的评分或位置偏移量。即应用在m x n的每个位置上都会有一个输出;
-
将一系列default boxes与网络顶层多个特征图中每个特征图单元相关联。default boxes,如图1中为3 x 3大小以卷积的方式放到特征图上,所以每个default boxes的位置相对于与它相关联的单元格是固定的。在每个特征图单元格中,我们预测方框相对于特征图单元格的偏移位置及其类别评分。例如,在一位置上每个方框有K个目标,分别计算其类别评分c和4个位置偏移量,则有(c+4)k个滤波器被应用在m x n特征图的每个位置上,产生(c+4) x k x m x n的输出。这里的default boxes与Faster-RCNN中的anchor boxes相似,但会被应用于多个分辨率的特征图上。
训练
与使用region proposals和pooling的检测器不一样的是ground truth信息需要被分配到由检测器产生的特定的输出上,当分配好后即可进行端到端的训练。训练还涉及到选择default boxes和尺度以及困难样本挖掘和数据扩增等策略。
匹配策略:
- 在训练时,需要先建立ground truth和default boxes的联系,开始使用jaccard overlap将ground truth box与default boxes匹配,然后将default boxes对任意ground truth的 jaccard overlap大于阈值(0.5)的进行匹配。这样可以使网络在多个重叠default boxes中进行预测,而不需要只选择最大重叠的一个。
default boxes尺度和长宽比的选择:
-
大多数卷积网络会随着层次加深而减少特征图的尺寸,这样不仅减少了计算量和内存消耗,也产生一些角度和尺度变换的不变性。为处理不同的物体尺度,一些方法建议将图像缩放到不同的大小,然后每个尺度独立处理后合并结果。但使用来自单网络多个不同层的特征图进行预测,同时共享所有的物体尺度的参数,也可以实现这个功能。之前有论文证明过使用低层次的特征图可以提高语义分割的质量,因为低层获取了更好的细节。则文中同时采用高层和低层的特征图用来做物体检测,图1中展示了使用的两个特征图(8 x 8和4 x 4)示意,还可以采用更多层。
-
每层的特征图都会有不同的感受野,而SSD中default boxes没必要与每层实际感受野相联系。要使特定特征图的对应位置针对于特定图像区域和物体尺度的检测,使用多个特征图去预测,则每个特征图的default boxes的尺度计算如下:
 ,其中Smin=0.2,Smax=0.95,即最底层对应0.2,最高层对应0.95。而对于default boxes的长宽比,设a为{1,2,3,1/2,1/3},则宽高分别为
,其中Smin=0.2,Smax=0.95,即最底层对应0.2,最高层对应0.95。而对于default boxes的长宽比,设a为{1,2,3,1/2,1/3},则宽高分别为。对于长宽比为1时,添加一个尺度为
的default boxe,则每个特征图位置上有6个default boxes。设置每个default boxe的中心为
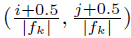 ,
,是第k个特征图的大小,
。在实际应用中可以设计一个default boxe的分布去适应针对的测试集。
困难样本挖掘:
- 在匹配阶段,多数的default boxs都是负样本,但并非所有负样本都使用。这里以每个default box的最高置信度进行排序,并选择最高的一些。使正负样本比例保持约为1:3,使训练更快更稳定。


总结
用特征图金子塔进行多尺度检测,在骨干网络后接几个卷积层,使输出特征图的尺度一层比一层小,形成多尺度的金字塔。金字塔上每个特征图都单独预测。最后将所有层的预测合并在一起做NMS。
其中还提了一个先验框的概念,在金子塔上每层分别使用的多个先验框(数量不一定相等),具体方式与anchor相似,以滑动窗口扫描(conv3x3 pad1,则输出特征图与输入尺度不变),每点上会对应着在该点上各个先验框的类别信息和位置信息,存储在个通道上。如某层采用6个先验框,则对分类输出的特征图的通道数应为6x(20+1)=126,20是类别1为背景,即输入特征图每个点会得到1x1x126的特征向量来表示其分类信息。同理对定位输出的则为6x4=24。
Ps:
- 因为输入图片大小固定,所以金字塔每层输出的维度也是固定的。
- 先验框主要设置的是长宽比,框的大小根据金字塔的层级按比例算。
- 虽然金字塔每层是单独预测的,但训练时,不能在每层单独接loss独立训练,应将每层联合起来。基本思路是将每层的特征图拼接到一起,统一接loss训练。所以就需要对金字塔每层用到了Permute调整维度和Flatten展开了,最后concat连接。