
代码:http://www.cs.berkeley.edu/˜rbg/rcnn
论文:Girshick, R, Donahue, J, Darrell, T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// Computer Vision and Pattern Recognition. IEEE, 2014:580-587.
论文算法概述
整个算法过程包含三个步骤:a、输入图像,搜索生成类别独立的物体候选框; b、使用大的CNN网络对各候选框提取固定长度的特征向量;c、利用线性SVM对特征向量进行分类识别。
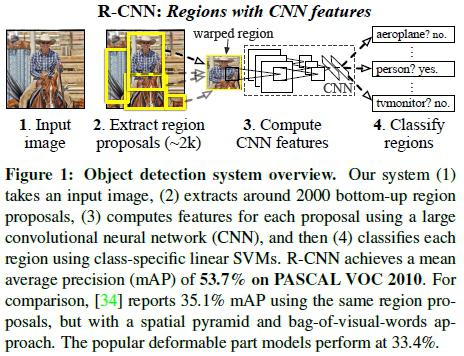
候选框搜索
使用selective search生成候选框,因为后面采用的网络结构是alexnet,则输入图像大小被限定为227*227,所以需要将候选框进行缩放填充处理。方式有很多种,如不管长宽比例直接缩放到对应大小,或将按比例将最长边缩放到对应大小后使用背景(框内均值、固定颜色等)将短边处填充到对应大小。文中采用的方式是先对候选框加padding=16,即框往外延伸16个像素后直接缩放到对应大小。在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则当做背景。
训练
-
网络有监督预训练:在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数作为初始的参数值,然后再fine-tuning训练。输入227*227的RGB图像,通过5个卷积层和2个全连接层,输出4096维特征向量。
-
fine-tuning:使用随机梯度下降法SGD在缩放和padding处理后的(VOC)样本上继续进行训练,将原CNN模型(AlexNet)中的分类层由原来的1000类改成N+1(1为背景)类,其他网络结构不变;SGD学习率为0.001(预训练模型学习率的1/10),即微调优而不破坏预训练模型的结果。在每个SGD迭代中,batch size大小128,包含32个正样本和96个负样本。
-
SVM训练与测试:当bounding box完整包含整量车的,才叫正样本;如果bounding box 没有包含到车辆则当做负样本。但当检测窗口只有部分包好物体,如何定义正负样本?文中从数值0,0.1,0.2,0.3,0.4,0.5中选择0.3,即当重叠度小于0.3的时候,我们就把它标注为负样本。当特征被提取出来后,为每个物体类别训练一个线性SVM分类器。而当训练样本数量过大导致内存不足的问题,文中使用困难负样本挖掘的方式(可参考DPM的论文:Object detection with discriminatively trained part based models)。
部分细节
- 使用CNN物体进行识别分类训练,在训练的时候最后一层softmax为分类层,而文中使用CNN进行特征提取,然后再把提取到的特征用于线性SVM分类器的训练。这是因为SVM训练和CNN训练过程的样本选取方式不一致,alexnet在训练时所采用的训练数据的标注比较宽松,如外接框包含物体一部分(IOU大于0.5)则可以作为正样本,需要大量的数据进行训练以防止过拟合。而SVM适用于小样本,对样本数据要求比较苛刻,要使外接框完全包含整个物体时才标注为目标。而文中采用selective search获取候选框,按照原alexnet中的训练模型无法取得较好的结果。
存在问题
-
训练过程繁琐:包含基于物体候选框使用log损失微调卷积网络;基于调优后的卷积特征训练SVM;训练bounding box回归器(参考DPM);
-
训练耗时,占用磁盘空间大。
-
每个候选框需要进行整个前向CNN计算导致测试速度慢:
总结
算法分三步,1)selective;2)将各候选框缩放填充至固定大小,用一个CNN对分别提取特定长度的特征向量;3)SVM对向量分类。主要短板在第2步,每个框都要重复输入CNN进行独立的计算。