
作者主页:http://disi.unitn.it/~uijlings/MyHomepage/index.php#page=projects1
论文:Uijlings J R R, Sande K E A V D, Gevers T, et al. Selective Search for Object Recognition[J]. International Journal of Computer Vision, 2013, 104(2):154-171.
论文算法概述
该算法用于在物体识别任务中找到物体可能存在的位置,提出的选择性搜索结合了穷举搜索和分割的优点。在分割中使用图像结构去指导采样过程,在穷举搜索中致力于找到所有可能的物体位置。主要目的在于减少搜索运算量的同时将所有目标可能存在的位置找出。 算法的设计以下几点需要考虑:1)适应不同尺度:穷举搜索通过改变窗口大小来适应物体的不同尺度,选择搜索性同样无法避免这个问题。算法采用了图像分割以及使用一种层次算法有效地解决了这个问题。 2)多样化:单一的策略无法应对多种类别的图像。使用颜色、纹理、大小等多种策略对分割好的区域进行合并。 3)速度.

使用层次聚类进行选择性搜索步骤
- 1、使用Efficient GraphBased Image Segmentation中的方法来得到区域集R; (P. F. Felzenszwalb and D. P.Huttenlocher. Efficient Graph-Based Image Segmentation. IJCV, 59:167–181, 2004)
- 2、计算区域集R里每个相邻区域的相似度S={s1,s2,…};
- 3、将相似度最高的两个区域其合并为新集,添加进R;
- 4、从S中移除所有与第三步中有关的子集;
- 5、重新计算新合并region与其他region的相似度;
- 6、跳至第3步,直至S为空;
- 6、使用一种随机的计分方式给每个区域打分,按照分数进行ranking,取出top k的子集,就是selective search的结果;
策略多样化
- 1、有两种多样化方法,一个是针对样本的颜色空间,另一个针对合并时候计算相似性的策略。
- 2、采用了8种颜色空间,包括RGB,灰度图,Lab,等等;
- 3、采用了4种相似性:颜色相似性(对应Figure1a的情况),纹理相似性(对应Figure1b的情况),小物体先合并原则,物体之间的相容性;
使用Selective Search进行物体识别
- 1、训练数据的产生:在训练数据上,标注出目标区域,如上图中绿色高亮区域的奶牛,将这些标注区域作为正样本。使用selective search产生目标假设区域(也就是若干个分割区域)。将分割区域的外接矩形和目标标注区域的重叠度在20%~50%之间的区域标注为负样本。我们规定负样本之间不能有超过70%的重叠。有了正样本和负样本之后,我们用的特征提取方法是:color-SIFT descriptors[32]+a finer spatialpyramid division[18]然后进行SVM训练。
- 2、迭代训练:采用迭代训练方式,在每次训练完成之后,挑选出false positives样本,并将其加入到训练样本中,其实这便是增加了困难样本数。使用其进行模型训练,直到收敛。

评价标准
文中定义了两种评价标准:Average Best Overlap (ABO)和Mean Average Best Overlap(MABO),令C为类别,G为目标区域,ABO为在特定类C中计算每一个目标区域g和由selective search产生的每个猜想区域l的最佳重叠部分,后求平均,即:

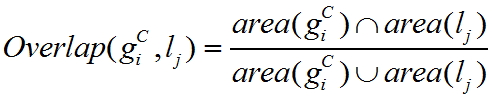
而MABO则为将每一类的ABO值求平均。
总结
一种传统的基于区域的目标检测算法,先用图割的方式得到大量区域框,然后通过计算相似度做两两合并,最后随机记分并排序,取前面K个子集作为检测结果。
PS:
-
图割是将图像用加权图抽象化,用两两像素点的灰度或彩色像素值的相似度做聚类;
-
与基于区域相对的是基于滑动窗口;
-
这里相似度计算主要是颜色和纹理;
-
评价是用平均最高重叠率ABO,即对一个特定类别,每个gt对所有区域框的最高重叠度,然后对所有gt的取平均,而重叠率为交集/并集;
-
随机计分数,论文是直接乘上随机数,或者可以机子采用一些别的策略,如根据区域框的融合次数赋予权重。