
主页:http://host.robots.ox.ac.uk/pascal/VOC/
样本统计:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/dbstats.html
简介
竞赛从2005年到2012年,现已结束。共含6个挑战任务:分类、检测、分割、动作分类、大规模识别和人体部件,其中分类、检测和分割为主要任务,该数据集多用于检测,其次为分割。
训练/验证集有1.1w图像,包含2.7w框选的物体和7k分割样本(2012:The train/val data has 11,530 images containing 27,450 ROI annotated objects and 6,929 segmentations)。
样本包含20类:人;动物:鸟、猫、牛、狗、马、羊;交通工具:飞机、自行车、船、公交车、小车、单车、火车;室内物品:瓶子、椅子、餐桌、盆栽、沙发、电视;
任务
-
分类/检测:20类,训练/验证集有1.1w图像,包含2.7w框选的物体。分类:判断测试图像中是否存在20类中某个类别的物体。检测:得出候选框及其类别标签。
-
分割:20类,训练/验证集有2.9k图像,包含6.9k分割目标。生成像素对像素的分割图,每个像素点会有类别信息。
-
行为分类:10类加“其他”,训练/验证集有4.6k图像,包含6.3k目标。在2012年这个竞赛有两个变体,取决于在测试图像中识别出行为的方式。一是通过人体周围紧密的边界框,二是通过一个落在身体上某个位置的点。后面这种的目的在于分析在只给定人的大概位置时,分类算法的性能。
-
大规模视觉识别:这个竞赛的目的是通过一个大型人工标记的ImageNet数据集的子集(1w个标签图片,描述上万个对象类别)作为训练来估计照片的内容。测试图像没有任何标注,完全由算法自己生成。在这个挑战的初始版本中,目标仅仅是识别图像中出现的主要对象,而不是指定对象的位置。
-
人体部件:训练/验证集有609张图像,包含850个目标。预测人体每个部件的位置与类别,包含头、手和脚。
数据包内容
整体数据会分有VOC2007和VOC2012两个包,每个包里面有5个大文件夹:Annotations、ImageSets、JPEGImages、SegmentationClass和SegmentationObject。
JPEGImages:包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片,以“年份_编号.jpg”格式命名的。图片的像素尺寸大小不一,但是横向图的尺寸大约在500 x 375左右,纵向图的尺寸大约在375 x 500左右,基本不会偏差超过100。
Annotations:含xml格式的标签信息,每一个xml文件都对应于JPEGImages文件夹中的一张图片,如下所示:
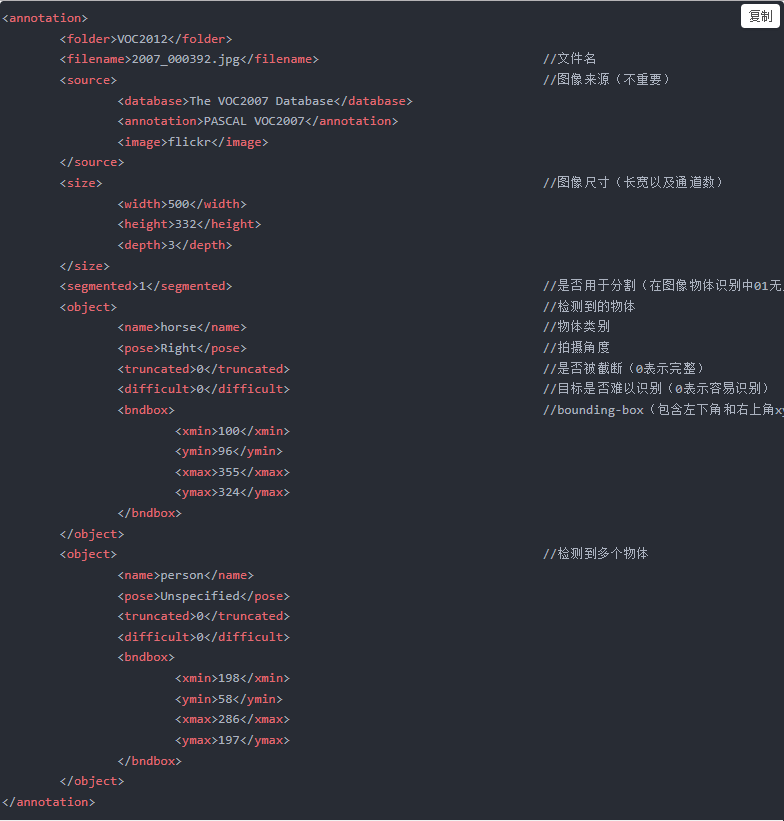
ImageSets:分4个文件夹,分别是Action、Layout、Main和Segmentation。其中Action下存放的是人行为分类数据(VOC2007上没有这一项);Layout下存放的是具有人体部位(头、手、脚)的数据;Segmentation下存放的是可用于分割的数据名;Main下存放的是各类数据出现的统计,总共分为20类,每类分开存放,如对aeroplane会有aeroplane_train、aeroplane_trainval.txt和aeroplane_val.txt三个文件,trainval为train和val的合并,每个文件内格式为“2011_003176 1”,前面为图片名字,后面的1表示该图片上有该物体出现,-1则表示没有。
SegmentationClass:含分割用的掩码标签数据,标注出每一个像素的类别 。
SegmentationObject:含分割用的掩码标签数据,标注出每一个像素属于哪一个物体。

测试方式
提交的结果需存储在一个文件中, 每行的格式为:
confidence会被用于计算mean average precision(mAP)。简要流程如下:
-
根据confidence对结果排序,计算top-1, 2, …N对应的precision和recall;
-
将recall划分为n个区间t in [t1, …, tn];
-
找出满足recall>=t的最大presicision;
-
最后得到n个最大precision,求它们的平均值,即为该类别的AP值:

上面代码给出的是voc07的计算方式。
而在voc2010在recall区间区分上有变化:假如有M个正样例,则将recall划分为[1/M, 1/(M - 1), 1/(M - 2), … 1](其余步骤不变)。对于每个recall值r,我们可以计算出对应(r’ > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。
注:输出的bbox与一个ground truth bbox的 IOU大于0.5,且类别相同,则为True Positive, 否则为False Positive。对于一个ground truth bbox, 只会有一个 true positive,其余都为false positive。
结果权衡指标
对于检测、分类、分割和行为识别任务,提交的数据都会计算每类的AP值(即为准确率precision和召回率recall所画的PR曲线下的面积),并写整体的mAP(多个类别AP的平均值) - link

-
在检测和分割任务中,常用的评价指标就是mAP。
-
VOC竞赛的分类任务为多标签图像分类任务,判断一张图像上是否存在某类物体,而一张图像可以同时存在多种类别的物体,所以评价不能用普通单标签图像分类的标准,即mean accuracy。因为这种多标签分类任务在本质上与检测有点相似,同样有漏检和误识的概念,所以也可画PR曲线算mAP。 - link
近期榜单数据(2018.08.21)
- 使用VOC2012数据集训练的结果(分类88.8, 检测:81.1, 分割84.0):



- 使用自己的数据集训练的结果(分类95.3, 检测:90.7, 分割89.0):


