
数据下载:https://www.msceleb.org/download/sampleset
简介
由微软为人脸识别任务提供的训练和测试集,其中的训练集包含10w(100k)人的100w(10M)张图片。这里的人脸识别任务主要分两个,1)从人脸图像中识别,并通过库中对应的entity keys(唯一的索引键值或机器ID号)得到其身份;2)与1类似,多了个限制条件,一些人的训练样本很少,即“Know you at One Glance”。

Challenge-1任务描述
从人脸图像中去识别一百万个名人,并通过这些人在知识库内唯一的entity keys来得到其身份。
Challenge-1训练集
提供的训练集包含10w个名人,由以下几个步骤进行收集:
-
根据流行程度从1M名人名单中选择10w个名人;
-
利用搜索引擎来为每个名人找到约100张图像,即会共有一千万张图像;
-
进行检测、裁剪和对齐人脸,同时也提供原始图的缩略图作为参考。
需要注意的是这些训练样本都是没有进行过人工的去噪的,即会有不少的错误标签,参赛者可以自行进行数据清洗。同时在竞赛中,这个数据集仅是为了帮助参赛者快速开始,不对额外的数据做限制,但鼓励参赛者将数据收集也看成是人脸识别挑战的一部分。
此外,当前提供的训练集MS-Celeb-1M.v1仅涵盖测试集合中的75%的名人,这就意味着基于提供的训练集的识别召回率不会高于75%。这主要是出于两个方面的考虑,首先,出于时间和资源的限制,只能准备这top10w的名人作为v1的数据集去帮助参赛者快速开始,后续这个量会慢慢增加;再者,这里鼓励参赛将数据收集处理作为这项挑战的关键问题来对待,并明确指出不限制额外的数据集。

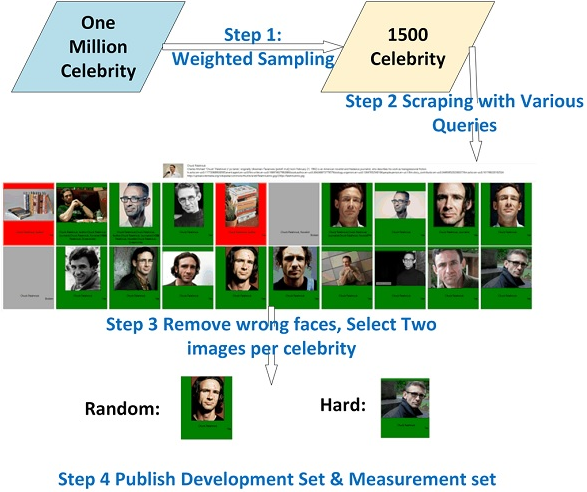
Challenge-1测试集
其构建步骤如下:
-
从一百万名人的列表中选择1500个名人,这选择的方式是75%的较出名的(即会出现在训练集中),25%的没那么出名的(即该部分未被纳入提供的训练集中);
-
通过多次搜索查询去截取图像以确保图像的差异,然后人工标注这些图像以确保标签无误。为了加大挑战性,混合入一些干扰图像在内。
-
对每个名人各选择两张图像去组成两个图像集。Random set:在这个子集里的图像是随机挑选的,每个人一张。这个集合可以揭示多少人被该模型涵盖在内进行测试。Hard set:在这个子集里的图像是与训练集中的其他图像是最不同的。每个人一张。这个集合是用来评估模型的泛化能力以及在复杂场景下的鲁棒性的。
该测试集的1500人中,保留500人用于开发和调试,剩下的1000人才是作为官方发布的测试集。
Challenge-2任务描述
在该挑战中,我们研究了low-shot人脸识别问题,目的是构建一个大规模的人脸识别器,能够识别大量的个体并具有较高的识别率和召回率。这里生成一个基准数据集,包含21K个人,每人50-100张图片,标签准确率达99%。将这个数据集分成以下两个子集:
Base set,含2w人,每人50-100张图像用于训练,5张图像用于测试。
Novel set,含1k人,每人1-5张图像用于训练,20张用于测试。
目标是研究当在base集中每人给定数十张,而在novel集中每个给定5张时,如何去训练一个算法在这两个数据集中都能表现得好。
这base集是用来帮助训练人脸识别特征的。使用一个标准的34层残差网络,在base数据集上训练,我们可以达到单模型在LFW上98.88%的准确率。
