
主页(需要翻墙):http://cocodataset.org/#home
评估代码:https://github.com/cocodataset/cocoapi
博客推荐:http://www.cnblogs.com/geekvc/p/6657369.html
简介
COCO是一个大规模的对象检测、分割和字幕数据集。直到2018年共开设有5项挑战,分别是Detection、Keypoints、stuff、Panoptic和Captions。其中Detection处理的是thing类别(如人、车、大象),Stuff处理的是stuff类别(草地、墙壁、天空),Panoptic则是两种同时处理,Captions为大规模场景理解(LSUM)任务。整体数据集有以下几个特点:目标分割;基于上下文的识别;超像素stuff分割;33w图像(>20w 标签);150w个目标实例;80个目标(object)类别;91个物品stuff类别;每张图片5个题注;25w个人体关键点样本。
Detection
简介
分两个检测任务,输出目标边界框或输出目标分割掩码(即为实例分割,如下图2中每个人颜色不同,图3每只羊颜色不同),注意在2018年该项挑战接收后者。训练、验证和测试集包含20w张图片和80个目标类别,每个目标都标注有精细的分割掩码。训练和验证集上有超过50w个目标分割实例,可供下载。

度量指标
分12项,AP和AR各6项:
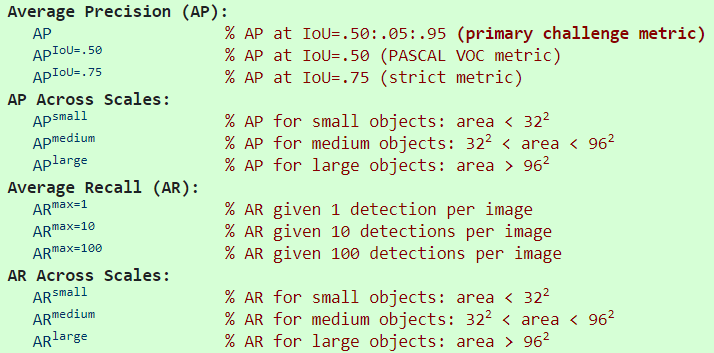
补充说明:
-
除非有另外的指定,AP和AR都是取多个IoU下的值得平均,如我们使用的10个IoU阈值0.50:0.05:0.95。这与传统的基于单一的0.5IoU为阈值的不同。
-
这里AP是取多个类别的平均,一般称之为mAP。这里不区分AP和mAP(AR和mAR)。
-
AP(跨10个IoU阈值和80个目标类别)来决定竞赛的冠军,这是最重要的评价指标。
-
在COCO数据集里,小目标会比大目标多。更具体地说,大约有41%的目标划为small(面积小于32x32),34%划为medium(32x32-96x96),24%为large(大于96x96)。其中的面积与目标分割掩码所占的像素点个数来决定。
-
AR是对每张图片在给定一定数量的检测个数下最大的召回率,取所有类别和IoU下的均值。
-
所有指标在计算时最多只涵盖每张图片上评分前100的检测结果(含所有类别)。
-
除了IoU计算(在边框或掩模上单独执行)之外,带有边界框和分割掩码的检测指标在各个方面都是相同的。
Keypoint
简介
COCO的关键点检测任务需要在具有挑战的、不受控制的条件下定位人体关键点,涉及同时检测人体和定位关键点(即人体位置需要自己检测)。训练、验证和测试集包含超过20w张图像和25w个标有关键点的实例(COCO中大部分的人体的大小都是medium和large的)。训练和验证集有15w人体和170w个关键点,可供下载。

评估方式
关键点检测的评估主要是参考目标检测,即用AP、AR及其变体。这些度量标准的关键在于得到GT目标和预测目标的相似度。如在目标检测中,IoU则充当了相似度的度量准则(边框和分割都一样),对IoU设定阈值去匹配GT和预测结果,并可以计算准确率-召回率曲线(PR曲线)。要在关键点检测任务上使用AP/AR,我们只需要去定义一个类似的相似度准则。所以这里定义了一个object keypoint similarity (OKS)去充当IoU的作用。
对于每个目标,GT关键点组成为[x1,y1,v1,…,xk,yk,vk],其中x和y是点的位置,而v为标识位,v=0表示未标点,v=1表示已标点但不可见,v=2表示已标点且点可见。对于每个目标,关键点检测器必须输出关键点的位置和对目标的置信度,输出也应与GT的格式一致,但里面的v在评估时是不需要用到的,所以关键点检测器不需要输出标志位v或置信度。令定义的OKS公式为:
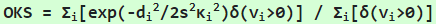
令di为GT和预测的关键点的欧式距离,vi是GT上的标志位(预测结果的vi没用到)。为计算OKS,我们将di输入到一个未归一化的标准差为ski的高斯函数,其中s是目标尺度,ki是每个关键点常量去控制衰减。对于每个关键点,它会产生一个在0和1之间的相似度。在所有标记的关键点(vi大于0)的相似度上取平均值,而vi=0的关键点不影响OKS。OKS范围是0-1,越大则越匹配。OKS与IoU类似,给定OKS后就可以计算AP和AR。
度量指标
分10项,AP和AR各5项(相比于检测,在scale部分没有small):
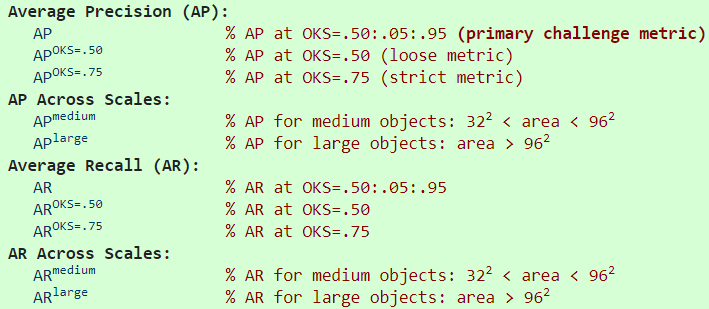
补充说明:
-
除非另有说明,否则AP和AR在多个OKS值(0.50:0.05:0.95)之间取平均值。
-
正如所讨论的,我们为每个关键点类型i设置κi=2σi。对于人来说,括号内为σ取值,鼻子(0.026)、眼睛(0.025)、耳朵(0.035)、肩膀(0.079)、手肘(0.072)、手腕(0.062)、臀部(0.107)和膝盖(0.087),脚踝(0.089)
-
AP(所有10个OKS阈值的平均值)将决定挑战胜利者。当考虑COCO的关键点性能时,这应该被认为是最重要的一个指标。
-
计算所有度量标准,每个图像最多允许20个最高得分检测(我们使用20个检测,而不是像对象检测挑战那样的100个,因为当前人是唯一具有关键点的类别)。
-
小对象(分割区域面积小于32x32)没有关键点标注信息,所以small部分不在训练和测试范围内。
-
对于没有标注关键点的对象(包括人群),我们使用宽松的启发式方法,以允许根据预测的关键点(hallucinated keypoints)(置于实际真实对象内以便最大化OKS)匹配检测结果。这与使用框/分割(boxes/segments)信息来忽略区域的处理非常相似。
-
无论被标记的还是可见的关键点的数量如何,每个对象都具有相同的重要性。我们不过滤只有几个关键点的对象,也不会根据存在的关键点的数量来加权对象示例。
Stuff
简介
(在2018未开设该项挑战)这里Stuff分割任务关注的是stuff类(草地、墙壁、空气等),是由均匀或重复的精细属性模式定义的背景材料,但没有特定或独特的空间范围或形状。而Detection关注的是thing类(人、车、大象等),具有特定的大小和形状,通常是由一部分一部分组成的。那么关注stuff的动机在于在COCO中stuff占了66%的像素,这使我们能够解释图像里重要的方面,包括场景类型。例如哪些类可能存在,以及它们的位置和这个场景的几何性质。 该任务中,包含有16.3wCOCO图像,其中训练集有11.8w,验证集有5k,test-dev有2w,test-challenge有2w。共含91个stuff类别和1类“其他”。

Panoptic
简介
Panoptic分割同时处理了stuff类和thing类,统一典型的语义和实例分割任务(语义分割指像素级分类,实例分割更高一级,不仅分类还要区分出是哪个实例)。目的是生成丰富、完整且连贯的场景分割,这对真实的视觉系统如自动驾驶和增强现实等很重要。
需要点出的是Detection中的thing类别如人、动物、工具等是可数的,而stuff类别如草地、天空等是没有定形区域的。所以之前的COCO任务是将这两项分开处理的,为了促进在统一框架下研究stuff和things,提出了Panoptic分割任务,而panoptic则定义为在视觉上所有能看见的东西。该任务对图像上每个像素会涉及一个语义标签和实例id,需要生成密集连续的场景分割图。
该Panoptic任务使用了所有COCO的标注图像,包含取自Detection任务的80个things类别和取自Stuff任务的91个stuff类别,然后重叠部分都由人工处理。

评估方式
当前存在的评价方式一般都只针对语义或实例分割某一项的,无法直接使用。这里引入了一个新的Panoptic Quality (PQ) metric,PQ以一种统一的方式评估所有类别(包括things和stuff)的性能。
计算PQ包含两个步骤:(1)分割图匹配和(2)PQ计算给定匹配。这两个步骤都是简单和有效的。首先,对于每一个图像,GT和预测的分割图在IoU阈值为0.5上匹配。由于Panoptic分割需要非重叠部分,如果使用了0.5的阈值,那么匹配是唯一的(在论文中有一个简单的证明)。也就是说,每段分割最多可以有一个匹配,所以获得匹配是很简单的。在匹配之后,每个分割段都分到三组:TP(匹配对)、FP(无法匹配的预测段)和FN(与GT不匹配)。
给定TP、FP和FN,每个类别的Panoptic质量(PQ)度量都是简单的:

PQ是按每个类别计算的,结果是跨类别的平均值。与无标签或拥挤区域有显著重叠的预测分割部分会从FP中过滤出来。最后,PQ可以分解为分割质量(SQ)项和识别质量(RQ)项的乘法。PQ = SQ x RQ的分解有助于算法分析:
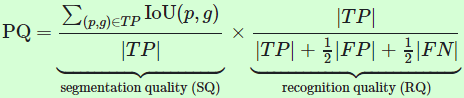
度量指标
分9项,PQ、SQ和RQ各三项:

补充说明:
-
PQ将决定挑战结果,而余下指标的提出只出于结果分析的目的。
-
PQ、SQ和RQ都是取所有类别的平均值,会包含stuff和thing的类别。
-
若只针对每一类别则PQ = SQ x RQ,但若是跨类别取平均则不能按这种方式分解。
Captioning
简介
大规模场景理解,是LSUM http://lsun.cs.princeton.edu/2017/ 的一部分。

近期榜单数据(2018.08.29)
Detection:

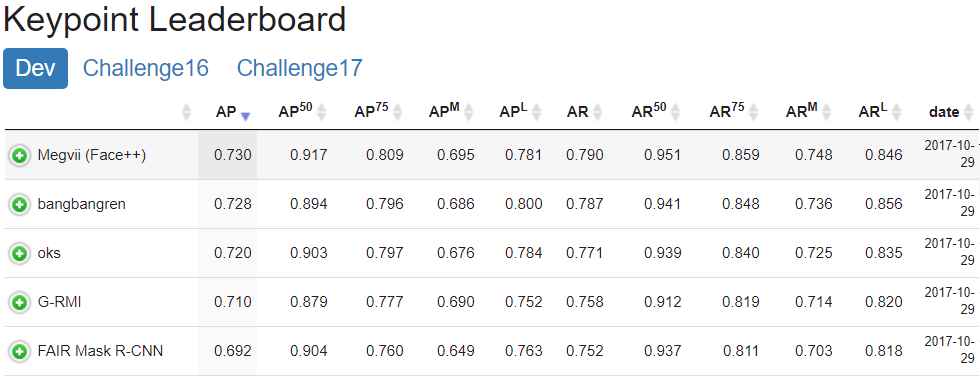
Keypoint:
Stuff:

Panoptic:无
Captioning:略