论文: Han S, Mao H, Dally W J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding[J]. Fiber, 2015, 56(4):3–7.
Github:https://github.com/songhan/Deep-Compression-AlexNet
论文算法概述
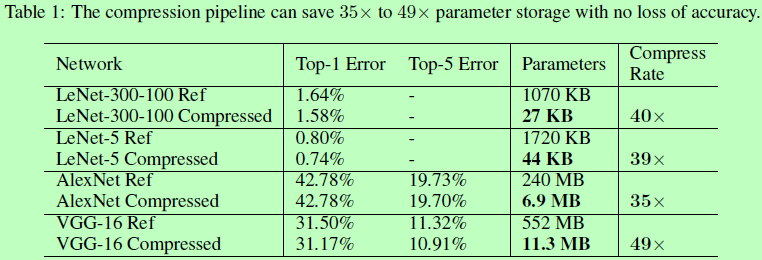
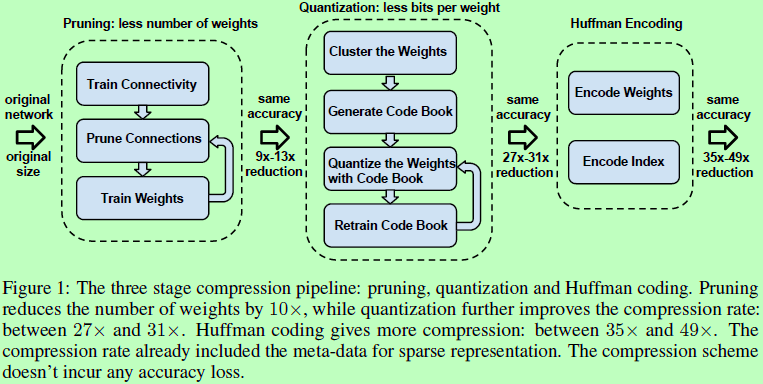
提出Deep Compression用于网络压缩,共包含压缩三个阶段,分别是剪枝Pruning,只留下网络的重要连接而把冗余的连接去掉;量化Quantization,可以使多个连接共享同样的权重,仅需要保存实际有效的权重及其索引即可;霍夫曼编码Huffman Coding,利用有效权重的有偏分布进行编码。整体可使模型减小35到49倍的大小而不影响其准确率。
压缩权重,未考虑速度。
Network Pruning
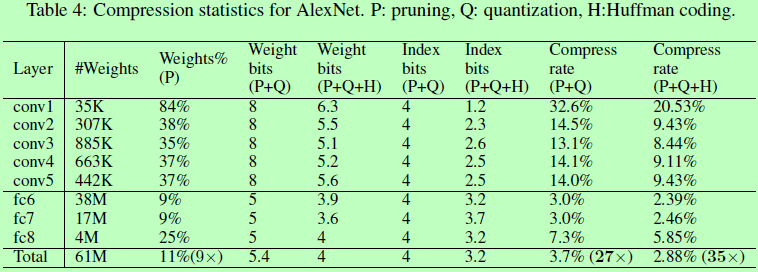
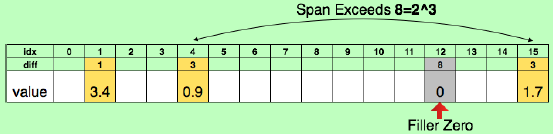
首先对网络进行普通的训练,然后将其中权重值小于某阈值的所有连接剪去,最后对裁剪过的网络进行再次训练。这里网络剪枝能能使Alexnet和VGG16的参数分别减少9倍和13倍。对于剪枝后的稀疏网络的保存使用compressed sparse row (CSR) 或compressed sparse column (CSC) 格式,仅需要2a+n+1个数,其中a为非0元素的个数,n为行数或列数。为进一步压缩,不保存绝对位置,以相对位置索引代替,而这索引在卷积层中用8bit来保存,在全连接层中用5bit保存。若需要的索引数值大于边界值,则补0示意,如图2所示。
Trained Quantization and Weight Sharing
该阶段通过减少表示每个权重所需要的bit数来进行压缩。如图3所示,假设一层网络(fc)有4个输入神经元和4个输出神经元,那么其权重和梯度都应是4x4的矩阵。权重被量化为4级,分别用4个颜色表示,所有在同一级的权重都共享相同的值,因此对于每层的权重只需要保存其在共享权重表centroids中的对应的下标即可。在训练更新的时候,所有梯度通过量级进行分组并归并到一起,乘以学习率,再由上次迭代得到的共享centroids减去得到结果。这样原始需要保存16个32-bit的权重就变成了保存4个32-bit的有效共享权重和16个2bit的下标索引。
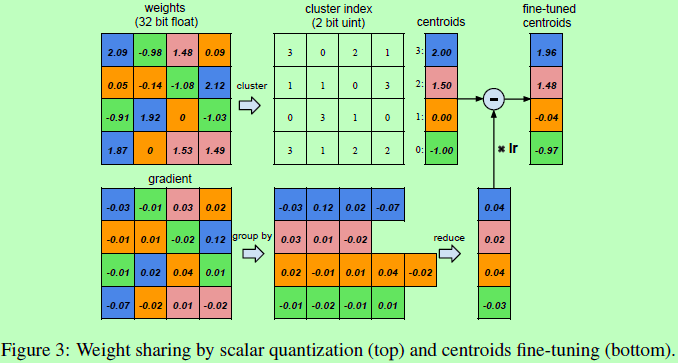
-
Weight sharing,对训练好的网络的每层使用K均值聚类来决定每层的共享权重,被聚集在同一个cluster里面的权重都将共享同一份权重。需要注意的是权重不跨层共享,每层各自聚类。
-
Initialization of shared weights,使用K均值需要进行初始化,初始化会对结果影响很大,作者试验了三种初始化方法:Forgy(random),density-based和linear initialization。以alexnet中conv3的权重为例,设13个clusters,如图4所示为三种不同的初始化方法的聚类结果。可见Forgy initialization和density-based initialization对分布的拟合情况较好。而大权重比小权重作用大,但只有少数这样的大权重,这样对于Forgy initialization和density-based initialization,聚类时就很容易将这些少数的大权重忽略掉。所以作者最终采用了没有这个问题的Linear initialization。

Huffman Codeing
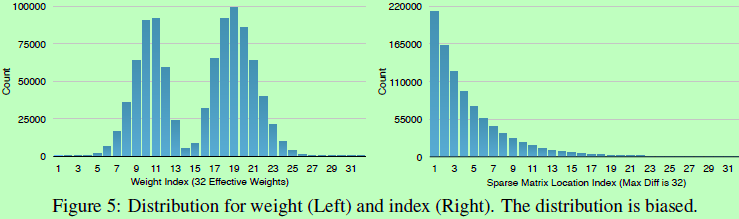
哈夫曼编码(最优前缀编码)是可变字长编码(VLC)的一种,用于数据的无损压缩。如图5所示,分别为AlexNet最后一层全连接层的量化权重和稀疏的索引矩阵的概率分布图。两个分布都是有偏好非均匀的,如量化权重的分布呈双波峰,而相对索引的稀疏矩阵的值很少超过20。所以较有利于进行哈夫曼编码。实验证明,使用哈夫曼编码对这非均匀分布进行编码可节省20~30的空间。
Experiment