
霍夫曼编码(属于熵编码的范畴)
一种可变字长编码,一种无损编码方法,又称为最佳编码,该方法完全依据信源字符出现的概率来构造其码字,对出现概率大的字符使用较短的码字,而对于出现概率低的字符使用较长的码字,从而达到压缩数据的目的;理论上不知道信源字符的概率分布,可根据大量数据的统计所得的概率分布来近似代替。但这种近似可能使霍夫曼编码无法达到最佳编码效能。
实现步骤:
-
统计信源字符序列中各符号出现的概率,将各字符出现的概率按由大到小的顺序排列;
-
将最小的两个概率相加,合并成新的概率,与其他概率重新按由大到小的顺序排列;
-
重新排列后,将两个最小的概率相加合并为新概率,重复步骤2直到最后两个概率之和为1.0;
-
对每个概率相加的组合中,概率大的指定为0,小的指定为1(也可调转),若相等,则随便指定。
-
找出由每一个信源字符到达概率1.0出的路径,顺序记录沿路径的每一个1和0的数字编码;
-
反向写出编码,即为该信源字符的霍夫曼编码。
特点:
-
在相同信源概率分布的前提下,它的平均码字长度比其他任何一种有效编码方法都短;
-
当图像灰度值分布很不均匀时,霍夫曼编码效率比较高(对不同概率分布的信源,霍夫曼编码的效率不同);
-
编码不唯一,体现在步骤4;
-
需建立在已知图像数据信息的概率分布基础上,若信源符号多,码表就会很大,会影响存储、编码和传输;
-
编码时,需两次读取图像数据。第一次得到数据概率,第二次以转换表格中的编码值代替图像数据。

香农-范诺编码(Shannon-Fannon,属于熵编码的范畴)
一种可变字长编码,理论基础是符号的码字长度Ni完全由该符号出现的概率来决定对于二进制编码,即有;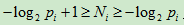
实现步骤:
-
将信源符号按其出现的概率由大到小顺序排列,若像个符号的概率相等,则相等的概率的字符顺序可以任意排序;
-
根据上式计算出各概率符号所对应的码字长度;
-
将各符号的概率累加,计算累加概率P,即P0=0、P1=P0、P2=P1+P0…;
-
把各个累加概率P由十进制转换为二进制;
-
将二进制累加概率的前位的数字,并省去小数点钱的“0.”字符,即为对应信源符号的香农-范诺编码。
-
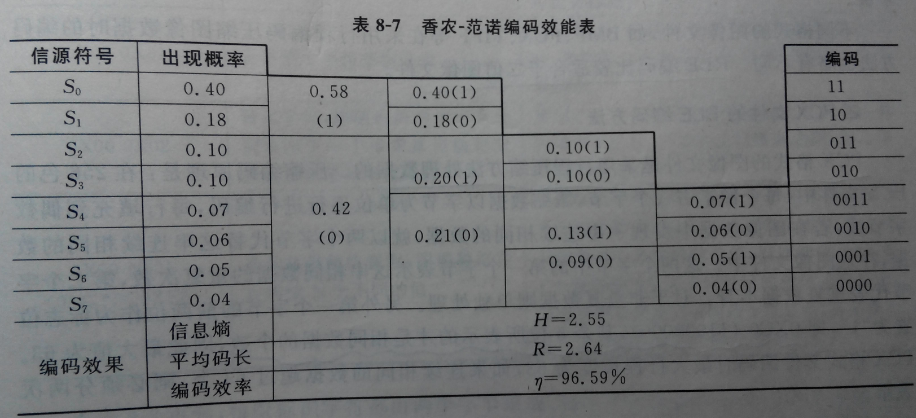
实现步骤二(对分法,效率比上面一种略高,但比霍夫曼编码略低):如图所示。
特点:
-
与霍夫曼编码一样,香农-范诺编码属于熵编码,需要知道各个信源字符的出现概率;
-
效率比霍夫曼编码略低;
行程长度编码(属于熵编码的范畴)
又称为RLE(Run Length Encoding)压缩方法。原理:在被压缩文件中寻找连续重复的数值,以重复次数和重复值自身两个值取代文件中连续的值,重复次数称为行程长度。(PCX文件和BMP文件采用该方法)。
算术编码(最常用的熵编码)
-
特点:算术编码是信息保持型编码,它不像霍夫曼编码,无需为一个符号设定一个码字。算术编码可分为固定方式和自适应方式,其中自适应方式无需先定义概率模型,适合于无法知道字符概率分布的情况,这也是算术编码由于霍夫曼编码的地方之一。同时,当信源字符出现的概率比较接近时,算术编码效率高于霍夫曼编码(算术编码一般比霍夫曼编码效能高5%以上)。
-
缺点:实现算术编码算法的硬件比霍夫曼编码的复杂。
-
原理:将编码的信源消息表示成0~1之间的一个间隔,即小数区间,消息越长,编码表示他的间隔就越小,由于以小数表示成间隔,因而表示的间隔越小所需的二进制位数就越多,码字就越长。信源中连续符号根据某一模式所生成概率的大小来缩小间隔,可能出现的符号要比不太可能出现的符号缩小范围少,只增加了较少的比特。
子带编码
采用带通滤波器将输入信号分割成N个不同的频带分量(子带),然后再分别对每个子带进行抽样、量化和编码。子带编码是一种频域编码,即将信号分解成不同频带分量来去除信号的相关性,从而得到一组互不相关的信号。
预测编码
依据某一模型,根据以往样本值对于新样本值进行预测,然后将样本的实际值和预测值相见得到一个误差,对这一误差值进行编码。预测编码可分为线性预测和非线性预测。(线性中最常用差分脉冲编码调制DPCM)
结论:
-
预测模型的复杂程度取决于线性预测中使用以前的样本数目,样本点越多,则预测器越复杂,最简单的预测仅使用前一个样本点,称为前值预测。
-
若采用x同一行的中xn的若干个已知像素样本值,如x1,x2,x3,…,x(n-1)来对xn进行预测,称为一维预测;
-
若采用同一行或前几行内的已知像素来预测,则称为二维预测;
-
若采用的已知像素不仅是前几行,而且还包括前几帧,则称为三维预测。
变换编码
-
变换编码主要包括DFT变换、K-L变换、WHT变换、DCT变换和小波变换编码等。基本思想是将空域中描述的图像数据经过某种变换,如DFT变换、DCT变换等二维正交变换,转换到新的变换域中进行描述,在变换域中达到改变能量分布的目的。将图像能量在空间域的分散分布,变为在变换域中的相对集中分布,从而实现对信源图像数据的有效压缩。
-
正交变换的意义:图像数据正交变换后不改变信源的熵值,变换前后图像的信息量没有损失。统计表明,经过正交变换后,数据的分布规律发生了很大的改变,像素之间的相关性下降,变换系数向新坐标系中的少数坐标集中,一般集中于少数的直流或低频分量的坐标点。
-
变换编码步骤: 1、原始图像分块;— 2、变换域采样;— 3、系数量化;— 4、解码与反变换。
-
对于分块:压缩的依据是基于子块图像像素的相关性,若子块选取太小,不利于压缩比的提高。若子块较大,压缩比也会变大,但计算量也随之变大。同时考虑到距离较远的像素相关性并不高,实际上过大的子块对压缩比的提高效果反而不好。
-
对于量化:由于变换后的系数是不相关的,因此具有更大的独立性和有序性,利用量化使图像数据得到压缩,量化使产生有损压缩的原因。
-
K-L变换:所有正交变换中性能最优,能完全去相关,舍去一些特征值较小的变换系数,所引起的均方差最小。缺点是K-L变换是一原始图像各子块协方差矩阵的特征向量座位变换后的基向量,因此K-L变换的基对不同图像是不同的,与编码对象的统计特征有关,这种变换基的不确定性使得K-L变换在应用中不方便。
-
DFT变换:性能佳,有快速算法,不足点在于图像子块的变换系数在边界出不连续而造成回复后的图像子块边界也不连续(存在Gibbs现象)。
-
DCT变换:用得最多,性能接近K-L变换,且变换矩阵与图像内容无关,还可避免DFT变换中图像子块边界出产生的跳跃和Gibbs现象。
-
沃尔什变换:算法简单,速度快,不足点在于性能比DCT差。