概述
一种树形结构,是一种哈希树的变种。有三个性质:
-
根节点不包含字符,除根节点外每一个节点都只包含一个字符;
-
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
-
每个节点的所有子节点包含的字符都不相同。
步骤:
-
从根结点开始一次搜索;
-
取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
-
在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
-
迭代过程……
-
在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
缺点:比较浪费空间(所以有人提出了双数组Trie);
双数组Trie树
-
两个数组:base[]、check[],其中base:数组中的每一个元素相当于trie树的一个节点; check:相当于当前状态的前一状态。
-
对于从状态s到状态t的一个转移,必须满足:check[base[s]+c]=s; base[s]+c=t; 其中c是输入变量。
基本思想:
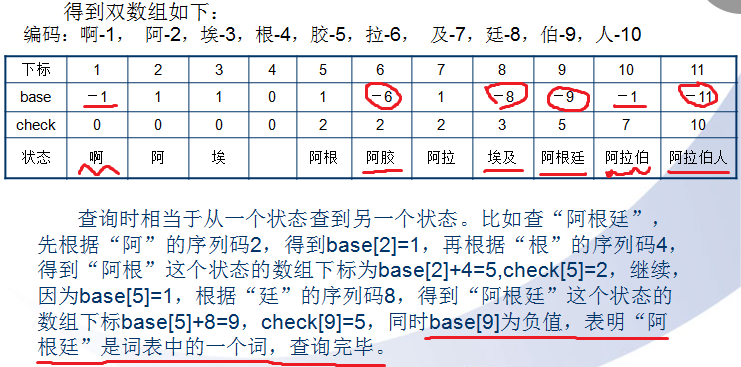
我们首先对词表中所有出现的10个汉字进行编码:啊-1,阿-2,唉-3,根-4,胶-5,拉-6,及-7,廷-8,伯-9,人-10(只有词以及可作为前缀的字有分配下标)。对于每一个汉字,需要确定一个base值,使得对于所有以该汉字开头的词,在双数组中都能放下。例如,现在要确定“阿”字的base值,假设以“阿”开头的词的第二个字序列码依次为a1,a2,a3……an,我们必须找到一个值i,使得base[i+a1],check[i+a1],base[i+a2],check[i+a2]……base[i+an],check[i+an]均为0。一旦找到了这个i,“阿”的base值就确定为i。用这种方法构建双数组Trie(Double-Array Trie),经过四次遍历,将所有的词语放入双数组中,然后还要遍历一遍词表,修改base值。因为我们用负的base值表示该位置为词语。如果状态i对应某一个词,而且Base=0,那么令Base=(-1)i,如果Base的值不是0,那么令Base=(-1)Base。
用上述方法生成的双数组,将“啊”,“阿”,“埃”,“阿根”,“阿拉”,“阿胶”,“埃及”,“阿拉伯”,“阿拉伯人”,“阿根廷”均视为状态。每个状态均对应于数组的一个下标。例如设“阿根”的下标为i=5,那么check的内容是“阿”的下标2,“廷”的序列码为x=8,那么“阿根廷”的下标为base+x=base[5]+8=1+8=9。
存在问题:
-
在数据结构上不可避免的存在空间浪费。
-
构造调整过程中,每个状态都依赖于其他状态,所以当在词典插入或删除词语的时候,往往需要对双数组结构进行全局调整,灵活性较差。