概述
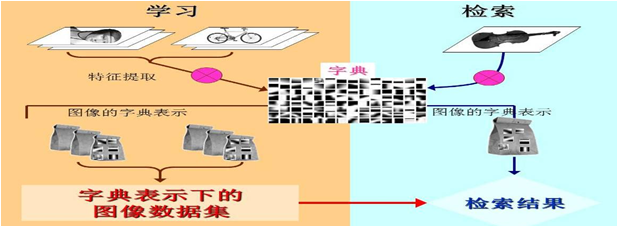
为什么要用BOW模型描述图像(因为用SIFT的计算量庞大)。
SIFT特征虽然也能描述一幅图像,但是每个SIFT矢量都是128维的,而且一幅图像通常都包含成百上千个SIFT矢量,在进行相似度计算时,这个计算量是非常大的,通常的做法是用聚类算法对这些SIFT矢量数据进行聚类,然后用聚类中的一个簇代表BoW中的一个视觉词,将同一幅图像的SIFT矢量映射到视觉词序列生成码本,这样每一幅图像只用一个码本矢量来描述,这样计算相似度时效率就大大提高了。
构建BoW码本步骤:
-
预处理。假设训练集有M幅图像,对训练图象集进行预处理。包括图像增强,分割,图像统一格式,统一规格等等。
-
提取特征。一般对每一幅图像提取SIFT特征(每一幅图像提取多少个SIFT特征不定)。每一个SIFT特征用一个128维的描述子矢量表示,假设M幅图像共提取出N个SIFT特征。
-
词典(码本)构造。用K-means对2中提取的N个SIFT特征进行聚类(即字典构建),聚类中心有k个(在BoW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量(某些文中说的“直方图统计”)。
-
码本矢量归一化。因为每一幅图像的SIFT特征个数不定,所以需要归一化。
-
图像检索。将要检测的图像用同样的方法提取特征并转化为词频矢量,使用分类器进行检索分类(分类器可以使用SVM等)。
缺点:BoW模型忽略了词典中的所有视觉词所表示的多种局部模式对应于原始图像中的图像块或区域之间的空间位置关系和语义信息,简单地说,就是BoW模型存在缺少空间信息和语义信息的不足的问题。
解决方法:通过在原始阁像屮划分规则的栅格(RegularGrid)、考虑局部特征和周围其他局部特征之间的空间排列(Spatial Layout)关系、空间金字塔匹配(SpatialPyramid Matching)或者事后验证几何关系(Verifying Geometric Relationships)的方法为BoW模型添加必要的空间位置信息;为了缓解其缺少语义信息的问题。