
介绍一下八个深度学习方面的技巧,尤其对于CNN应用于图像相关的课题:1、数据扩增;2、数据预处理;3、网络初始化;4、训练过程中一些技巧;5、激活函数的选择;6、多种正则化;7、从实验图和结果发现insights; 8、如何集合多个深度网络;参考资料链接
数据扩增
-
数据扩增的方式有很多,如水平翻转、随机切割、颜色抖动,还有的是可以尝试将多个操作合在一起等。另外也可以对hsv颜色各通道数值进行一定调整。
-
Krizhevsky et al.在2012年训练AlexNet时提出一种fancy PCA的方法。在实践中,可以在所有训练样本的像素RGB数据集进行PCA,然后对每张图像的RGB分量只需要加上
,
,其中
和
分别是第i个特征向量和RGB像素值的3*3的协方差矩阵的特征值,ai为一个随机值取自0均值和标准偏差0.1的高斯函数。需要注意的是每个ai对一张图像的所有的像素只能使用一次。这就是说,当模型训练时再次遇到同一张训练图像,会重新生成ai来进行数据扩增。they claimed that “fancy PCA could approximately capture an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination”. 对于分类的性能,,这种设计在ImageNet 2012中减少了top-1的错误率1%。
数据预处理
-
数据中心化与归一化;
-
数据白化(PCA);
网络初始化
-
全零初始化(不能这样做):假如全部权值都设为0或相同的数,就会计算相同梯度和相同的参数更新,即没有对称性。在理想的情况下,有合适的数据归一化,可以很合理地猜测到大约会有一半权重是positive一半是negative的,就容易认为将初始权重设为0是一个不错的选择,但这样做是错误的。因为如果在神经网络中的每个神经元计算同一个输出,那么它们就会在反向传播计算相同的梯度且更新相同的参数。即如果初始权重都设置成一样,就没有了每个神经元不对称的来源。
-
使用小的随机数进行初始化(用处不大):仍然期望各参数接近0,符合对称分布,来设各个参数,但最后的效果没有实质性提高。这种方式中神经元在开始时都是随机且唯一的,因此它们会有区别地进行更新并作为分离的部分在网络中组合一起。但这样似乎对最终性能只能起到相对较小的作用。
-
调整神经元的方差(未考虑到ReLUs):每个细胞源输出的方差归到1,通过除以输入源的个数的平方,w=np.random.randn(n)/sqrt(n); 其中randn是高斯函数,n是它的输入个数,这样保证了所有神经元都有大概相同的输出分布,并且以经验为主地提高了收敛的速度。。
-
最近推荐的做法(ICCV, 2015,specifically for ReLUs):神经元方差设定为2/n,n是输入个数。 w=np.random.randn(n)*sqrt(2.0/n),即权值w为正态分布上的采样数乘以sqrt(2.0/n) –» K. He, X. Zhang, S. Ren, and J. Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.(http://arxiv.org/abs/1502.01852)InICCV, 2015.
训练过程
-
滤波器和池化的大小设定:在训练中,输入图像大小常取2的幂,如32 (e.g., CIFAR-10), 64, 224 (e.g., common used ImageNet), 384、512。而且,使用小的滤波器(如33)和小步长(1)没有补丁padding很重要,这样不仅减少了参数的数量而且提高了整个深度网络的准确率。同时,上面的一个例子,33的滤波子步长为1,可以保留图像或特征图的空间尺寸。至于池化层,常采用的大小是2*2。
-
学习率:Ilya Sutskever [2],推荐使用mini-batch分离梯度。因此,如果你修改了mini-batch的大小,就不要经常性地修改学习率(LR)。为了得到一个合适的LR,利用验证集是个有效的方法。通常,一个典型的初始学习率是0.1。在训练过程中,你可以发现先暂停训练,然后将LR除以2(或5),然后再继续训练,可能会不错的效果。
-
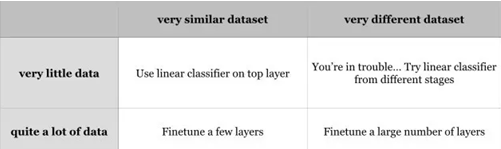
预训练模型上进行微调:现在很多先进的深度网络被发布了,如Caffe Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)and VGG Group(http://www.vlfeat.org/matconvnet/pretrained/)。感谢预训练模型的泛化能力,你可以将这些预训练模型直接应用在你的应用中。为了更好地在你的数据集中提高分类效果,一个很有效的方法是在你的数据集上对预训练模型进行调整。表格中显示,这两种重要的因素分别是新数据集的大小和新数据集与该预训练模型所采用的原数据集的相似程度,不同的调优策略应用在不同的情况。
微调策略
-
你的新数据集与预训练模型采用的数据集很相似,而你的新数据集只有少量数据,你可以仅仅在预训练模型的顶层基于特征提取情况训练一个线性分类器;
-
如果你有很多数据在手上,则可使用小的学习率LR去微调预训练模型顶部的一些层;
-
如果你的数据集与预训练模型采用的数据集相差较大,但拥有足够的训练图片,则需要使用小的学习率在你的数据集上微调大量的层以提高效果。
-
如果你的数据集不仅只有少量样本,而且跟原数据集也相差很大,你就麻烦了,可以尝试在各个阶段训练线性分类器
-
数据少,仅仅训练一个线性分类器会比较好;
-
数据差异大,在网络顶层训练分类器就不好,因为该预训练模型包含了很多数据集特定的特征(dataset-specific features),而应在网络前面的激活层和特征层做SVM分类器训练。
对于数据集,Caltech-101与imagenet相似,都以物体为中心;而Place Database则与imagenet相差较大,因为前者以环境为主。
激活函数
-
Sigmoid:将实数范围限定在[0,1],Sigmoid函数在以往经常被使用,因为它可以很好地将神经元的燃烧速度表现出来:from not firing at all (0) to fully-saturated firing at an assumed maximum frequency (1).而最近Sigmoid函数失宠,主要是因为两个原因:
-
Sigmoid因为饱和而失去梯度。一个很不好的性质是,Sigmoid神经元在激活状态接近0或1时,该区域梯度都几乎是0。回想起反向传播中为达到目的,局部梯度会被乘以这一输出的梯度。因此,如果局部特征很小,它就会使梯度消失,使没有信号会通过神经元到达它的权重并递归到它的数据中。另外一个需要注意的是在初始化Sigmoid神经元的权重时需要防止饱和,例如初始化权重过大则多数神经元会饱和且网络将几乎不能学习。
-
Sigmoid的输出不是以0为中心的。很不想见到的是在神经网络后面处理层中,神经元会接收到不以0为中心的数据。这样在动态梯度下降法中,如果进入神经元中的数据通常都是正的,那么整个权值梯度w要不全为正,或者全为负(取决于整体的梯度表达式f)。这会导致在权重更新上的锯齿状的动态梯度,但如果在一个batch数据中将梯度求和来更新权值,有可能会相互抵消,从而缓解上述的影响。这是一个缺点,但相比起激活的饱和带来的问题小很多。
-
-
tanh(x):将实数范围限定在[-1,1],与sigmoid函数相似,依然激活饱和,但输出以0为中心。因此,在实践中tanh非线性比sigmoid的非线性好。
-
ReLU(Rectified Linear Unit):有以下一些优点和缺点
-
优点)与sigmoid/tanh相比,其运算简单,非指数形式不会饱和。
-
优点)已被证明可以加速随机梯度收敛,这被认为可能是由于其线性和非饱和形式导致的。
-
缺点)ReLU很容易die,例如一个很大的梯度通过ReLU神经元去更新权重时会造成该神经元将在各数据点上无法继续有效(不激活),即以后梯度通过该神经元都只会得到0。例如,学习率设置得太高时,你可能会发现有40%的神经元失效了(在整个训练过程中都不被激活)。
-
-
Leaky ReLU、Parametric ReLU(a是学习的得到)、Randomized ReLU(a是在给定的范围内随机采样得到的,而测试用的是固定的)
从表格中可以看到ReLU在三个数据集中都不是表现得最好的:对于Leaky ReLU,较大的倾斜会取得较好的效果;PReLU在小的数据集中很容易过拟合(训练错误小,测试错误不如意),但也比ReLU好;另外RReLU在NDSB上很明显的胜过其他激活函数,表明RReLU可以克服过拟合,因为这个数据集比CIFAR-10/CIFAR-100的训练数据少;总之,三种ReLU的变型在三个数据集上都比原始的ReLU效果好,而且PReLU和RReLU看起来是个不错的选择,


正则化(查阅基础算法–深度学习基础–正则化)
Insights from Figures
-
图一:学习率是很敏感的,从图1中可以看出,一个很高的学习率会得到一个很奇怪的损失弧线。一个很低的学习率会使你的损失下降得很慢,甚至经过一个epoch;相反一个高的学习率会使损失在开始的时候下降得很快,但会陷入局部最优。为了得到一个好的学习率,如红线所示,它的损失弧线表现得很平滑并在最后达到一个很好的效果。
-
图二:epochs表示全部样本训练一次,因此一个epoch中包含有很多个mini batches。如果将每个训练batch的分类损失结果画出来就会得到图二。1》与图一相似,如果损失弧线走向趋势比较接近线性,这意味着学习率低;2》如果下降得比较少,则学习率可能太高了;3》还有这弧线的宽度与batchsize有关,如果看起来很宽,就表明每个batch的变化太大,意味着你应该加大batchsize。
-
图三:关于准确率弧线。如图三所示,红线是训练准确率,绿线是验证准确率。当验证准确率收敛时,红线和绿线的间隙会显示你的深度网络的性能。如果间隙大,表示你的网络在训练数据集中会得到不错的准确率,但在测试集中准确率较差,很显然你的模型在训练集中过拟合了。因此,你应提高你的网络的正则化能力。然而,没有间隙意味着低准确率也不行,代表着你的模型的学习能力较差。在这种情况下应提高模型的能力。
集成方法
在机器学习中,集成方法即训练多个学习器然后组合在一起使用,是一种先进的方法。众所周之,集成方法通常会明显地比是使用单种方法的准确率要高,并且集成方法也已经在实际应用上获得了很大的成功。在实践中,特别是挑战或竞赛,几乎所有第一名和第二名都是使用集成方法。下面介绍几种集成方式:
-
Same model, different initialization. 使用交叉验证去决定最佳的超参数,然后利用这个最好的超参数集使用不同的随机初始化对多个模型进行训练。这种方法的风险是这种多样化仅仅是因为初始化。
-
Top models discovered during cross-validation. 使用交叉验证去决定最佳的超参数,然后选取最好的几个模型去集成。这样提高了集成的多样性,但有包含次优模型的风险。在实践中,这样可以很好地表现,因为在交叉验证后不需要额外地对模型进行再训练。实际上,你可以直接从Caffe Model Zoo (https://github.com/BVLC/caffe/wiki/Model-Zoo)中选择多个先进的深度模型进行集成。
-
Different checkpoints of a single model. 如果训练成本很贵(很麻烦),一些人在以往单独一个网络中选取不同的checkpoints(例如在每个epoch后面)而获得有限效果,现将它们集成起来。显然,这缺乏了多样性,但仍然能够工作得很好。这种方法的优点的简单。
-
Some practical examples. 如果你项目与高级图像语义、静态图像中事物识别有关,一个很好的集成方法是在不同的数据集中提取不同且互补深度表示来训练多个深度模型。例如,在Cultural Event Recognition (https://www.codalab.org/competitions/4081#learn_the_details) 的竞赛中,与ICCV’15(http://pamitc.org/iccv15/) 相关,我们使用5个不同的深度模型在ImageNet (http://www.image-net.org/), Place Database (http://places.csail.mit.edu/) and the cultural images supplied by the competition organizers (http://gesture.chalearn.org/).上进行训练。然后我们提取5个互补的特征并将它们看成是多视点数据。Combining “early fusion” and “late fusion” strategies described in [7], we achieved one of the best performance and ranked the 2nd place in that challenge. Similar to our work, [9] presented the Stacked NN framework to fuse more deep networks at the same time.
训练中类别不平均问题:
问题:一些类拥有大量的训练数据,一类数据量有限(不平衡的训练数据对整个网络有负面效果)
解决方法:
-
直接上采样和下采样数据。“P. Hensman, and D. Masko. The Impact of Imbalanced Training Data for Convolutional Neural Networks. Degree Project in Computer Science, DD143X, 2015.”
-
采用剪切的办法。“X.-S. Wei, B.-B. Gao, and J. Wu. Deep Spatial Pyramid Ensemble for Cultural Event Recognition. In ICCV ChaLearn Looking at People Workshop, 2015.”
-
采用fine-tuning策略,将数据分割为两个部分,大数据集合小数据集,先微调大的类,再微调小类。