概述
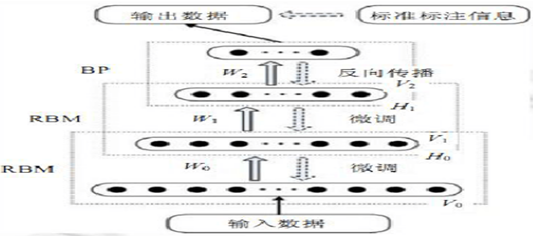
在该算法中,一个DBN被视为由若干个RBM堆叠在一起,训练时可通过由低到高逐层训练这些RBM来实现,使用非监督贪婪逐层方法去预训练获得权值,最后微调。
训练步骤:
-
首先充分训练第一个 RBM;
-
固定第一个 RBM 的权重和偏移量,然后使用其隐性神经元的状态,作为第二个 RBM 的输入向量;
-
充分训练第二个 RBM 后,将第二个 RBM 堆叠在第一个 RBM 的上方;
-
重复以上三个步骤任意多次;
-
微调(使用全局学习算法,如BP算法)
Hinton建议,经过这种方式训练后,可以再通过传统的全局学习算法(如反向传播算法)对网络进行微调,从而使模型收敛到局部最优点。所以传统的DBN在最后一层设置 BP 网络,接收 RBM 的输出特征向量作为它的输入特征向量,有监督地训练实体关系分类器.而且每一层 RBM 网络只能确保自身层内的权值对该层特征向量映射达到最优,并不是对整个 DBN 的特征向量映射达到最优,所以反向传播网络还将错误信息自顶向下传播至每一层 RBM,微调整个 DBN 网络.RBM 网络训练模型的过程可以看作对一个深层 BP 网络权值参数的初始化,使DBN 克服了 BP 网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点。
当然,最上面有监督学习的那一层,根据具体的应用领域可以换成任何分类器模型,而不必是BP网络。