感受野
每个神经网络的隐藏单元都有一个其自身的感受野,通常是指感受场(例如:源节点的输入层)的区域,其中充分的感觉刺激(如模式)将引起相应。就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。感受野如下图右变所示。

CNN(Convolutional Neural Networks卷积神经网络)
CNN是一种特殊的神经网络,参数少,容易层叠出深度结构。最重要的是,它根据label,就能有效提取出稀疏特征,将其卷积核可视化之后,居然达到了近似生成模型的效果,确实可怕。卷积神经网络通过卷积层和子采样层的相互配合来学习原始图像的特征。通过BP算法来完成权值的更新;输入的特征映射可以应用不同的卷积核卷积得到;以下是对自然图片的学习结果,Hinton指出,自然图片的参数可视化后,应该近似Gabor特征。

局部接受域(局域感受野):指的是每一网络层的神经元只与上一层的一个小邻域内的神经单元连接,使得神经元可以从输入图像中提取初级视觉特征,如特定角度的边缘,端点和拐角等,后续各层可以组合这些初级特征,从而得到更高层的特征。局部接受域客观上减少了需要训练的权值数目。减轻了Gradient Vanish梯度弥散问题,使得早期CNN在非ReLU激活情况下,就能构建不退化的深度结构。
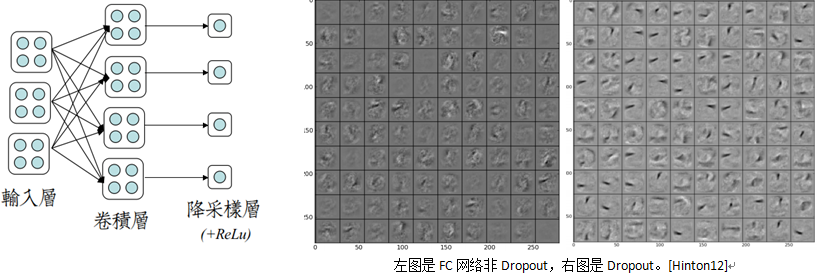
其中,降采样层、为非全连接的”虚层”,也就是说,真正构成压力的只有卷积层。Hinton的Dropout观点来看,块状神经元使得一个卷积核在一张feature map中固定学习一部分输入,而不依赖全部输入。这是为什么卷积核的可视化效果较好的原因。因为它模仿出了输入的局部特征。正则化+dropout 改善了过拟合的现象。
权值共享:迫使那些共享同一组权值的神经元在输入的不同位置检测同一种特征,可以多加一些滤波器种类,每种滤波器参数不一样,表示它提出输入图像的不同特征。卷积神经网络把每层共享相同权值的神经元组织成一个二维平面,称为特征图(FeatureMap),这使得输入中的平移变化,会以同样的方向和距离出现在特征图的输出中,却不引起其他形式的变化。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。权值共享大幅减少需要训练的权值数目,从而大大降低对训练样本的需求。局部最小值问题也被减轻,因为参数量的减少,使得目标函数较为简单,CNN解决梯度弥散是使用的权值共享的策略。
隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。那么隐层的神经元个数怎么确定呢?它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐层的神经元个数就是(1000x1000 ) / (10x10)=100x100个神经元了,假设步长是8,也就是卷积核会重叠两个像素,那么……我就不算了,思想懂了就好。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的贫富差距就越大。
亚采样:子采样操作无重叠的组合输入中同一大小的所有子区域(一般是对该层输入图像的一个 n×n 大小的均值池化或最大池化),降低输入图像的分辨率,使得卷积神经网络对输入的局部变换具有一定的不变性,模拟初级视皮层中的复杂细胞。
通过结合当前任务的先验知识约束其设计,一个可调整大小的多层感知器能够学习一个复杂的、高维的和非线性的映射。其次,突触权值和偏置水平可以周而复始地通过训练集的简单BP(反向传播)算法进行学习。
卷积网络的核心思想是将:局部感受野、权值共享以及亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、倾斜、扭曲不变性。
Alex Krizhevsky在(ImageNet Classification with Deep Convolutional_Alex2012)对传统CNN提出的几点改进,使得CNN结构变得更加强大:
-
将Sigmoid系激活函数全部换成ReLu,这意味着多了稀疏性,以及超深度结构成为可能(如GoogleNet),即也为解决梯度弥散作出贡献。
-
添加局部响应归一化层,在计算神经学上被称作神经元的侧抑制,根据贾扬清说法,暂时似乎没发现有什么大作用。[知乎]Caffe中之所以保留着,是为了尊敬长辈遗留的宝贵成果。
-
弱化FC层神经元数:ReLu使得特征更加稀疏,稀疏特征具有更好的线性可分性。[Glorot11]这意味着FC层的多余? GoogleNet移除了FC层,根据贾扬清大牛的说法:因为全连接层(Fully Connected)几乎占据了CNN大概90%的参数,但是同时又可能带来过拟合(overfitting)的效果。这意味着,CNN配SVM完全成为鸡肋的存在,因为FC层+Softmax≈SVM
-
为卷积层添加Padding,使得做了完全卷积,又保证维度不会变大。
-
使用重叠降采样层,并且在重叠降采样层,用Avg Pooling替换Max Pooling(第一仍然是Max Pooling)获得了5%+的精度支持。
-
使用了Hinton提出的DropOut方法训练,减轻了深度结构带来的过拟合问题。
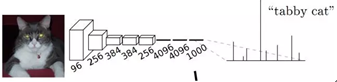
CNN在深度学习的影响:自2012年AlexNet提出并刷新了当年ImageNet物体分类竞赛的世界纪录以来,CNN在物体分类、人脸识别、图像检索等方面已经取得了令人瞩目的成就。通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。
以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述, 比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率。例如,下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类上响应最高。