
概述
Haar-like特征(也可以是gabor+PCA、等) + 积分图方法 + adaboost + 级联 的人脸检测。
AdaBoost算法学习

弱分类器个数T的确定

具体依据
-
强分类器的检出率(误判率)随着阈值的减小而增大,随着阈值的增加而减小。极端的情况,如果将阈值设置为0,那么强分类器会将所有的样本分类为人脸,这时检出率和误判率最大,为100%;
-
增加弱分类器的数目可以减小误判率。
两个基本概念
-
强分类器的训练检出率=被正确检出的人脸数与人脸样本总数的比例;
-
强分类器的训练误判率=被误判为人脸的非人脸样本数与非人脸样本总数的比例
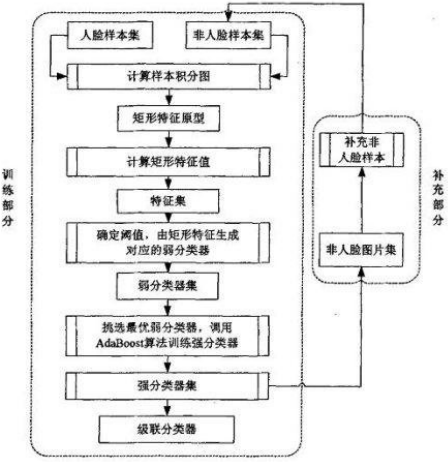
什么是级联
级联是一个多级方法,每个学习器关联一个置信度,在分类中如果所有前驱学习器的结果均不够确信,我们才使用下一个学习器。置信度函数被设置为最高的后验;
主要思想:在初期使用简单的分类器处理大多数实例,而更为复杂的分类器仅用于少数实例,因此并不显著增加总体复杂度。
级联示意图如下:级联多个强分类器,每通过一个分类器后会去掉一部分候选区域,如果分类器足够强,通过第一个分类器后除了目标外都被去掉了,则不需要继续后面的分类,否则继续用分类器筛选,都不剔除则为目标。即前级处理简单,后级处理困难。如人脸检测中,大量的检测窗口只需要最初的几层简单的判断就可被淘汰掉。(级联的是强分类器,而adaboost中是对各个弱分类器进行筛选后组成 强 分类器)
训练L层级联分类器的步骤如下:
-
训练第i层强分类器Hi(每层的训练由adaboost完成);
-
保存强分类器Hi的参数,即各弱分类器的参数、强分类器的阈值以及被Hi误判为人脸的非人脸样本;
-
补充非人脸样本集,组合前i层强分类器对候选非人脸样本进行检测,将被误判为人脸的非人脸样本加入到样本集中(人脸样本不更新); (4)训练第i+1层强分类器。
级联的优势:
-
降低训练难度:对于一个强分类器与一个L层的级联分类器,假设它们误判率相同为F,可知级联分类器的各层强分类器的误判率要大于F,训练一个误判率较高的强分类器难度相对较小。
-
降低非人脸样本选取难度:训练级联结构的分类器,通过程序“自举”非人脸样本,逐层增加训练难度,可以很好的解决非人脸样本选取的难题。
自举:在1个容量为n的原始样本中重复抽取一系列容量也是n的随机样本,并保证每次抽样中每一样本观察值被抽取的概率都是1/n(复置抽样)。
Haar分类器
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost + 级联;
Haar-like特征:一类矩形以一个方向在一个位置为一个Haar特征,可作为一个弱分类器。
积分图方法:加快Haar-like特征的计算速度。
Adaboost算法:使用训练样本集对多个弱分类器(或说基学习器)进行测试筛选,得到各个分类器的正确率,小于1/2的舍去,大于1/2的留下,并根据正确率大小赋予相应的权值,采用加权投票组合成一个强分类器。其训练思想为将实例的抽取概率改成误差的函数。
级联:组合多个强分类器,根据识别率给各个强分类器赋予一个相应的置信度,逐层通过强分类器去掉候选项,如输入一副图像,通过第一层强分类器就被排除了,则不用通过后续的强分类器。前级处理简单,后级处理困难